The following article explains the key differences between Heap tables and Clustered tables.
While working with tables in SQL Server, users often face the dilemma to use clustered tables or heap tables. Tables which don’t have clustered indexes are called Heap Tables and those having clustered indexes are called Clustered Tables. A Clustered index basically reorders the way in which records are stored physically in a table. The data pages are contained in the leaf nodes of a clustered index.
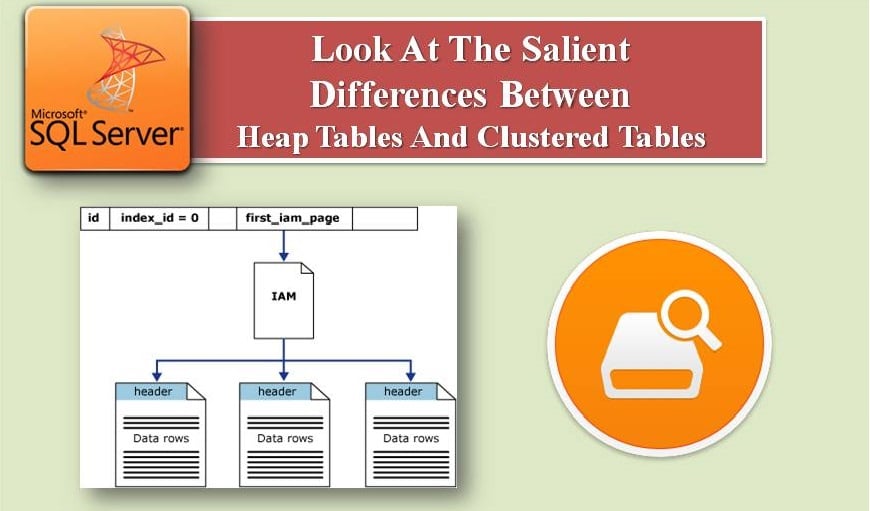
The article discusses these two table types in a more detailed manner.
Clustered and Heap Tables
The clustered tables provide the users more benefits than heap tables as they help users in using indexes to find rows quicker than heap tables and physically store the data/records by rebuilding the clustered index.
Your physical data can become fragmented if there are more INSERT, DELETE and UPDATE activities against the tables in your data. It is known that fragmented data can add to wasted and undesirable space because if you run a query it has to read several more pages as there are now more partly full pages. Let’s find out ways to solve the fragmentation issue of data.
Difference between Heap and Clustered Table
Fragmentation problem can be tackled down by determining the need to have a clustered index in your table/s or not. After all, it’s the clustered or heap index that regulates your table’s physical storage. Any table in your database can have only one type of index. To make a choice, we must understand the basic differences between these two which are as follows.
- In heap, there is no order in storing data but in Clustered, data storing has an order depending on clustered index key.
- Data pages are not linked in Heap whereas in Clustered table, they are linked and there is faster sequential access.
- Heap have 0 index_id value and Clustered have 1 index_id value for sys.indexes catalog view
- Clustered Index retrieves data quicker than heap table as there is Clustered Index key
Fragmentation
Based on the differences between Clustered and Heap Tables one can solve the problem of fragmentation. Fragmentation occurs because of the use of INSERT, DELETE and UPDATE activities. However if you have Heap Table and there is only INSERT activity, then fragmentation won’t occur. If you are using sequential index key (Identity Value) and have only INSERTS, then your clustered index won’t get fragmented. But if you use lots of INSERTS or DELETES then the tables will become fragmented.
So it’s advised to use Clustered Index as it is dependent on Index key and consumes less space. New records can be written to already existing pages in the available free space.
To determine the use of either heap or clustered table, you can also try running DBCC SHOWCONTIG or new DMV as both these commands can give you insight regarding the fragmentation issues in your tables. In the clustered table, fragmentation can be resolved by reorganizing or rebuilding your clustered index.
Investing in a SQL Server repair tool is a must for companies who use the MS SQL Server database on their production servers. In fact it can prove to be a lifesaver in the event of a database crash.
Author Introduction:
Victor Simon is a data recovery expert in DataNumen, Inc., which is the world leader in data recovery technologies, including repair mdb and sql recovery software products. For more information visit https://www.datanumen.com/