1. Wprowadzenie do SQL Server Replikacja
1.1 Co to jest SQL Server Replikacja?
SQL Server Replikacja to zestaw technologii umożliwiających kopiowanie i dystrybucję danych oraz obiektów bazodanowych z jednej bazy danych do drugiej, a następnie synchronizację między bazami danych w celu zachowania spójności. Funkcja ta umożliwia tworzenie i utrzymywanie wielu kopii danych na różnych serwerach i w różnych lokalizacjach, zapewniając dostępność i niezawodność danych.
1.2 Cel i korzyści replikacji
SQL Server replikacja zaspokaja wiele krytycznych potrzeb biznesowych i zapewnia znaczące korzyści w zakresie zarządzania bazami danych i dystrybucji danych:
- Dystrybucja danych pomiędzy lokalizacjami: Replikacja umożliwia udostępnianie danych między biurami regionalnymi lub lokalizacjami na całym świecie, zwiększając wydajność operacyjną poprzez zapewnienie lokalnego dostępu do wymaganych danych. Zmniejsza to opóźnienia w sieci i zapewnia lepszą wydajność użytkownikom rozproszonym geograficznie.
- Duża dostępność i odzyskiwanie po awarii: Dzięki utrzymywaniu replik krytycznych danych na wielu serwerach, replikacja zapewnia redundancję, która chroni przed awariami sprzętu i katastrofami. W przypadku awarii serwera głównego, replikowane kopie mogą służyć jako źródła zapasowe, minimalizując przestoje i utratę danych.
- Równoważenie obciążenia i skalowalność: Replikacja rozkłada operacje odczytu na wiele serwerów, zapobiegając sytuacji, w której pojedynczy serwer stanie się wąskim gardłem. Takie podejście zwiększa wydajność systemu i umożliwia skalowanie infrastruktury w poziomie wraz ze wzrostem danych i potrzeb użytkowników.
- Raporty i analizy w czasie rzeczywistym: Przeniesienie zapytań dotyczących raportowania i analiz na replikowane serwery zmniejsza obciążenie produkcyjnych baz danych. Użytkownicy mogą uruchamiać złożone zapytania analityczne na danych niemal w czasie rzeczywistym, bez wpływu na systemy operacyjne, co zapewnia zarówno wydajność, jak i aktualność danych.
- Integracja i konsolidacja danych: Replikacja ułatwia scalanie danych z różnych źródeł w jeden, skonsolidowany widok. Jest to szczególnie przydatne dla organizacji z wieloma oddziałami, które muszą agregować dane w centrali, lub dla tworzenia scentralizowanych magazynów danych z rozproszonych systemów operacyjnych.
2. SQL Server Architektura replikacji i komponenty
SQL Server Architektura replikacji składa się z kilku połączonych ze sobą komponentów, które współpracują ze sobą, aby dystrybuować i synchronizować dane w całej infrastrukturze bazy danych. W tej sekcji omówiono główne komponenty, w tym wydawców, dystrybutorów, subskrybentów, publikacje, artykuły, subskrypcje oraz agentów koordynujących przepływ danych między nimi:
- Wydawca: Wydawca jest SQL Server na przykład, że hostto jedna lub więcej baz danych zawierających dane do replikacji. Służy jako autorytatywne źródło w topologii replikacji.
- Dystrybutor: Dystrybutor jest SQL Server Instancja zarządzająca przepływem danych między wydawcami a subskrybentami. Instancja dystrybutora hostjest bazą danych dystrybucyjnych, w której przechowywane są metadane replikacji i transakcje.
- Abonent: Subskrybent to SQL Server instancja, która odbiera i przechowuje replikowane dane od wydawców. Pojedyncza instancja subskrybenta możeost wiele baz danych subskrybentów, z których każda pobiera dane z różnych publikacji.
- opublikowany: Publikacja definiuje, jakie dane będą replikowane i w jaki sposób będą dystrybuowane do subskrybentów. Grupuje powiązane artykuły i ustala metodologię replikacji, która ma zastosowanie do wszystkich zawartych w niej obiektów.
- Artykuł: Artykuł jest podstawowym elementem replikacji, reprezentującym pojedynczy obiekt bazy danych, który zostanie rozpowszechniony wśród subskrybentów.
- Subskrypcja: Subskrypcja ustanawia relację między publikacją a subskrybentem, określając sposób i czas dostarczania danych do bazy danych docelowej.
- Agenci: Agenci to wyspecjalizowane procesy, które wykonują faktyczną pracę polegającą na przenoszeniu i synchronizowaniu danych pomiędzy komponentami replikacji.

3. Rodzaje SQL Server Replikacja
SQL Server oferuje kilka typów replikacji, z których każdy jest przeznaczony do konkretnych scenariuszy dystrybucji danych i wymagań biznesowych. Zrozumienie cech, zalet i ograniczeń każdego typu jest kluczowe dla wyboru odpowiedniego podejścia dla danego środowiska.
3.1 Replikacja migawek
Replikacja migawkowa tworzy migawkę danych, które mają zostać opublikowane w określonym czasie, a następnie dystrybuuje dokładną, kompletną kopię do subskrybentów. Nie monitoruje kolejnych zmian do momentu wygenerowania kolejnej migawki. Replikacja migawkowa to najprostsza forma replikacji, dzięki czemu nadaje się do scenariuszy, w których dane zmieniają się rzadko lub w których dopuszczalne jest posiadanie lekko nieaktualnych danych.
Typowe przypadki użycia obejmują dystrybucję danych referencyjnych, takich jak cenniki czy kursy walut, które są okresowo aktualizowane, dostarczanie początkowych zestawów danych dla magazynów danych oraz scenariusze, w których pełne odświeżenie danych jest preferowane zamiast śledzenia poszczególnych zmian. Na przykład firma może wykorzystać replikację migawek do dystrybucji zaktualizowanych katalogów produktów do oddziałów raz dziennie.
Głównymi zaletami replikacji migawek są jej prostota, niskie wymagania konserwacyjne oraz możliwość replikacji danych bez kluczy podstawowych. Ma ona jednak istotne wady, takie jak duży wpływ na generowanie migawek z powodu blokad tabel, duże opóźnienia między aktualizacjami oraz nieefektywność w przypadku dużych zbiorów danych lub danych często zmieniających się. Wszelkie modyfikacje wprowadzane u subskrybentów są…ost kiedy zostanie zastosowana następna migawka.
3.2 Replikacja transakcyjna
Replikacja transakcyjna dostarcza zmiany od wydawcy do subskrybentów w czasie niemal rzeczywistym, replikując poszczególne transakcje w miarę ich występowania. Rozpoczyna się od początkowej migawki, która ustala punkt odniesienia, a następnie stale monitoruje dziennik transakcji pod kątem zmian w opublikowanych artykułach i dostarcza je subskrybentom stopniowo.
Replikacja transakcyjna idealnie sprawdza się w scenariuszach serwer-serwer wymagających wysokiej przepustowości i niskich opóźnień. Typowe zastosowania obejmują poprawę skalowalności i dostępności poprzez przeniesienie operacji odczytu na serwery abonenckie, obsługę magazynowania danych i raportowania z danymi w czasie niemal rzeczywistym, integrację danych z wielu lokalizacji w centralnej lokalizacji oraz przeniesienie przetwarzania wsadowego na dedykowane serwery. Na przykład platforma e-commerce może wykorzystywać replikację transakcyjną do utrzymywania zsynchronizowanych danych o zapasach w regionalnych bazach danych.
Zaletami replikacji transakcyjnej są niskie opóźnienia w dostarczaniu danych, wysoka przepustowość dla dużych wolumenów transakcji oraz możliwość wprowadzania niereplikowanych modyfikacji u subskrybentów. Wadami są: większa złożoność w porównaniu z replikacją migawkową, konieczność posiadania kluczy podstawowych w replikowanych tabelach oraz ryzyko przerwania replikacji w przypadku wystąpienia konfliktów, takich jak naruszenie klucza podstawowego u subskrybentów.
3.3 Replikacja scalająca
Replikacja scalająca została zaprojektowana specjalnie dla środowisk, w których subskrybenci muszą pracować w trybie offline lub z niestabilną łącznością, a następnie synchronizować zmiany, gdy połączenie jest dostępne. Ten typ replikacji umożliwia niezależną zmianę danych zarówno u wydawcy, jak i u subskrybentów, śledzenie zmian za pomocą wyzwalaczy i tabel metadanych oraz automatyczne scalanie modyfikacji podczas synchronizacji.
Replikacja scalająca jest przeznaczona dla aplikacji mobilnych i rozproszonych środowisk serwerowych, w których zachodzą autonomiczne zmiany. Przykłady zastosowań obejmują automatyzację działu sprzedaży, w której użytkownicy mobilni pracują offline i synchronizują się później, systemy punktów sprzedaży działające niezależnie i okresowo konsolidujące dane, a także aplikacje rozproszone, w których wiele lokalizacji musi aktualizować współdzielone dane. Na przykład sieć handlowa może wykorzystać replikację scalającą, aby każdy sklep mógł zarządzać lokalnym stanem magazynowym, jednocześnie synchronizując się z centralnym systemem magazynowym.
Zalety replikacji scalającej obejmują obsługę autonomicznych subskrybentów, którzy mogą wprowadzać zmiany, tolerancję na przerwy w łączności sieciowej oraz elastyczne rozwiązywanie konfliktów. Wady obejmują większą złożoność konfiguracji i konserwacji, obciążenie wydajności związane ze śledzeniem metadanych i wyzwalaczy, dodawanie kolumn unikatowych identyfikatorów do tabel oraz potencjalne konflikty wymagające zarządzania i rozwiązywania.
3.4 Replikacja typu peer-to-peer
Replikacja peer-to-peer opiera się na replikacji transakcyjnej i umożliwia wielu instancjom serwera (trzem lub więcej węzłom) działanie jako równorzędni partnerzy, przy czym każdy węzeł pełni jednocześnie rolę nadawcy i subskrybenta. W tej topologii wszystkie węzły przechowują identyczne kopie danych i mogą obsługiwać zarówno operacje odczytu, jak i zapisu, zapewniając prawdziwie rozproszone środowisko z wieloma serwerami nadrzędnymi.
Replikacja peer-to-peer jest odpowiednia dla aplikacji wymagających skalowalności operacji odczytu i wysokiej dostępności. Przykłady zastosowań obejmują aplikacje internetowe, które dystrybuują zapytania katalogowe do wielu węzłów, zachowując jednocześnie spójność danych, scenariusze wymagające konserwacji lub aktualizacji bez przestojów poprzez indywidualne wyłączanie węzłów, a także aplikacje globalne z centrami danych w różnych regionach. Na przykład, globalna organizacja wsparcia oprogramowania może korzystać z replikacji peer-to-peer w biurach w różnych strefach czasowych, aby każda lokalizacja miała lokalny dostęp do aktualnych danych.
Zalety replikacji peer-to-peer obejmują lepszą wydajność odczytu dzięki skalowaniu poziomemu, wyższą dostępność dzięki wielu aktywnym węzłom oraz spójność danych niemal w czasie rzeczywistym. Do wad należą: konieczność posiadania wersji Enterprise Edition, złożoność w zarządzaniu topologiami wielowęzłowymi, konieczność identycznego schematu i danych we wszystkich węzłach oraz potencjalne konflikty, gdy operacje zapisu nie są odpowiednio partycjonowane.
3.5 Replikacja dwukierunkowa
Replikacja dwukierunkowa to specyficzna topologia replikacji transakcyjnej, zaprojektowana specjalnie dla środowisk dwuserwerowych, w których oba serwery muszą wymieniać między sobą zmiany. Każdy serwer publikuje dane i subskrybuje te same dane z drugiego serwera, tworząc prosty, dwukierunkowy przepływ synchronizacji. Chociaż replikacja peer-to-peer może również obsługiwać dwa węzły, replikacja dwukierunkowa zapewnia lepszą wydajność w tym konkretnym scenariuszu.
Replikacja dwukierunkowa jest odpowiednia w scenariuszach wymagających dwóch aktywnych serwerów z synchronizacją danych, takich jak konfiguracje aktywny-aktywny dla wysokiej dostępności lub aplikacje rozproszone geograficznie, gdzie każda lokalizacja wymaga lokalnego dostępu do zapisu. Topologia wymaga starannego zaprojektowania aplikacji w celu podziału aktualizacji danych i zapobiegania konfliktom.
Do zalet należą: zoptymalizowana wydajność w scenariuszach dwuserwerowych, prostsza konfiguracja w porównaniu z replikacją peer-to-peer, synchronizacja niemal w czasie rzeczywistym oraz niższe obciążenie niż w przypadku replikacji scalającej. Do wad należą: ograniczenie do dokładnie dwóch serwerów, brak wbudowanego rozwiązania konfliktów, wymagającego starannego projektowania aplikacji, oraz konieczność stosowania odpowiednich strategii partycjonowania w celu zapobiegania konfliktom.
3.6 Subskrypcje z możliwością aktualizacji
Subskrypcje z możliwością aktualizacji rozszerzają replikację transakcyjną, umożliwiając subskrybentom wprowadzanie sporadycznych zmian w replikowanych danych, które następnie są propagowane z powrotem do wydawcy i innych subskrybentów. W przeciwieństwie do replikacji scalającej lub topologii peer-to-peer zaprojektowanych do częstych aktualizacji dwukierunkowych, subskrypcje z możliwością aktualizacji są przeznaczone do scenariuszy, w których główny przepływ danych jest jednokierunkowy (wydawca-subskrybenci), ale subskrybenci okazjonalnie muszą wprowadzać poprawki lub aktualizacje.
Aktualizowane subskrypcje są odpowiednie w scenariuszach, w których most Aktualizacje odbywają się u wydawcy, ale sporadyczne aktualizacje są konieczne u subskrybentów, takich jak biura terenowe, które głównie odczytują dane, ale muszą wprowadzać lokalne poprawki lub aktualizacje. Topologia wymaga starannego planowania, aby zminimalizować konflikty i zapewnić spójność danych.
Do głównych zalet należy ograniczenie liczby operacji zapisu u subskrybentów przy jednoczesnym zachowaniu wydajności replikacji transakcyjnej. Wady to zwiększona złożoność, potencjalne konflikty wymagające rozwiązania, narzut wydajnościowy wynikający z protokołu zatwierdzania dwufazowego w trybie natychmiastowej aktualizacji oraz wymóg, aby wszystkie replikowane tabele miały klucze podstawowe.
3.7 Porównanie różnych typów replikacji
| Typ replikacji | Czas aktualizacji | Liczba wydawców | Kierunek | Użyj scenariuszy |
|---|---|---|---|---|
| Migawka | Punkt w czasie | 1 | One direction (Wydawca → Subskrybenci) | Rzadko zmieniające się dane referencyjne (cenniki, kursy walut) |
| Transakcyjny | Blisko prawdziwego czasu | 1 | One direction (Wydawca → Subskrybenci) | Scenariusze o wysokiej przepustowości (inwentaryzacja e-commerce, magazynowanie danych, raportowanie) |
| Łączyć | Okresowy (po podłączeniu) | 1 | Dwukierunkowy (Wydawca ↔ Subskrybenci) | Aplikacje mobilne, pracownicy offline (automatyzacja sprzedaży, usługi terenowe) |
| Peer-to-Peer | Blisko prawdziwego czasu | Wiele (3 lub więcej) | Dwukierunkowy (wszystkie węzły) | Globalne wdrożenia obejmujące wiele centrów danych (biura na całym świecie z lokalnym dostępem do odczytu i zapisu) |
| dwukierunkowa | Blisko prawdziwego czasu | 2 | Dwukierunkowy (oba serwery) | Konfiguracje typu aktywny-aktywny z dwoma centrami danych (wysoka dostępność w dwóch lokalizacjach) |
| Aktualizowane subskrypcje | Blisko prawdziwego czasu | 1 | Głównie w jednym kierunku (sporadycznie aktualizacje w odwrotnym kierunku) | Oddziały, które głównie czytają, ale okazjonalnie aktualizują (lokalne poprawki) |
4. Konfiguracja SQL Server Replikacja
4.1 Wymagania wstępne i wymagania
4.1.1 Wymagania programowe
SQL Server replikacja wymaga zgodności SQL Server wersje dla wszystkich uczestników topologii. Wersja dystrybutora musi być co najmniej taka sama jak wersja wydawcy, a subskrybent może znajdować się w odległości dwóch wersji od wydawcy. Na przykład, SQL Server Wydawca z 2016 r. może replikować SQL Server Subskrybenci z 2012, 2014, 2016, 2017 lub 2019 roku.
4.1.2 Wymagania dotyczące uprawnień
Konfiguracja replikacji wymaga określonych uprawnień na każdym poziomie. Członkowie stałej roli serwera sysadmin mogą wykonywać wszystkie zadania związane z konfiguracją replikacji. Aby uzyskać bardziej szczegółowe uprawnienia, użytkownicy muszą być członkami roli bazy danych db_owner dla baz danych wydawcy i subskrybenta.
4.2 Krok 1: Konfiguracja dystrybucji
Konfiguracja dystrybucji to pierwszy krok konfiguracji SQL Server replikacja.
Aby skonfigurować dystrybucję za pomocą SQL Server Studio zarządzania:
- Połącz się z SQL Server instancja w SQL Server Studio Zarządzania.
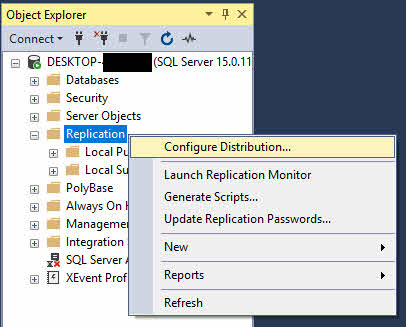
- W Eksploratorze obiektów kliknij prawym przyciskiem myszy Replikacja folder i wybierz Skonfiguruj dystrybucję.

- W Kreatorze konfiguracji dystrybucji kliknij Następna na stronie powitalnej.

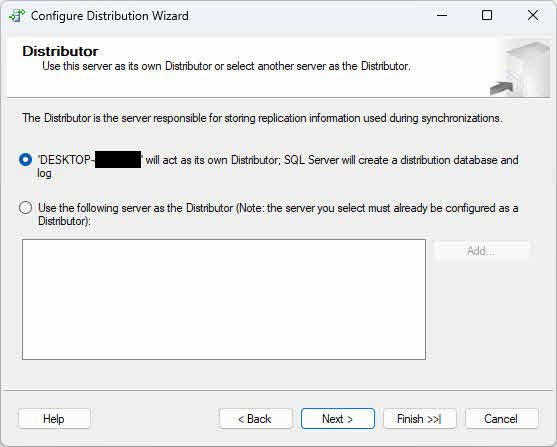
- Na Dystrybutor wybierz jedną z następujących opcji, w zależności od wymagań dotyczących topologii:
- Lokalny dystrybutor: Wybierz opcję „ServerName będzie działać jako własny Dystrybutor; SQL Server „utworzy bazę danych dystrybucji i dziennik”, jeśli chcesz, aby wydawca i dystrybutor działali na tej samej instancji (bieżącej instancji). Ta konfiguracja jest prostsza w konfiguracji i odpowiednia dla mniejszych środowisk lub gdy opóźnienie sieciowe między wydawcą a dystrybutorem mogłoby powodować problemy.
- Zdalny dystrybutor: Wybierz „Użyj następującego serwera jako dystrybutora” i kliknij Dodaj Aby określić zdalny serwer dystrybucyjny, jeśli chcesz przenieść przetwarzanie dystrybucji na osobną instancję. Ta konfiguracja poprawia wydajność przy dużych wolumenach replikacji poprzez rozłożenie obciążenia na wiele serwerów. Konieczne będzie podanie nazwy zdalnego dystrybutora i określenie hasła, którego wydawca będzie używał do łączenia się z dystrybutorem.
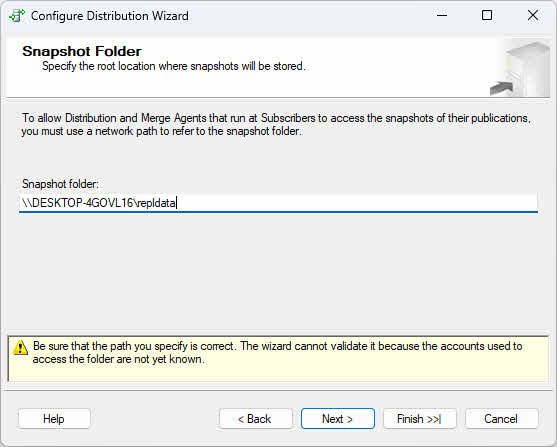
- Kliknij Następna Aby określić lokalizację folderu migawki. Użyj ścieżki UNC (takiej jak \\nazwa_serwera\udział\folder) zamiast ścieżki lokalnej, aby zapewnić dostępność w całej sieci.
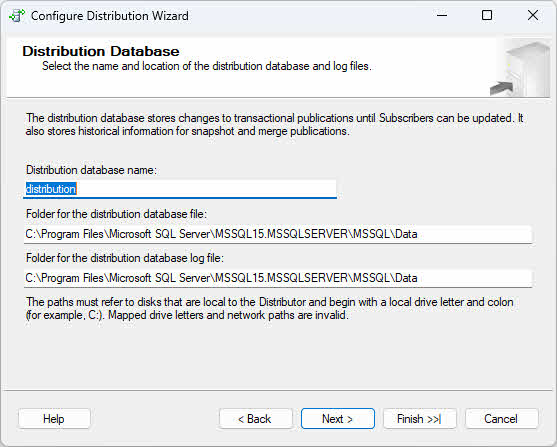
- Na Baza danych dystrybucji stronę, zaakceptuj domyślną nazwę bazy danych dystrybucji (zwykle „dystrybucja”) lub określ nazwę niestandardową, a następnie skonfiguruj lokalizacje plików danych i dziennika.
- Na Wydawcy
Sprawdź, czy bieżący serwer jest włączony jako wydawca. Jeśli skonfigurujesz bieżący serwer jako dystrybutora, możesz dodać kolejnych wydawców, którzy będą korzystać z tego dystrybutora.

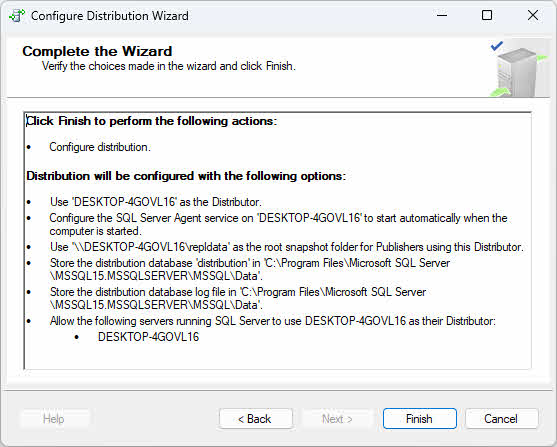
- Przejrzyj działania kreatora i kliknij Zakończ aby skonfigurować dystrybucję.
4.3 Krok 2: Utwórz publikację
Po skonfigurowaniu dystrybucji następnym krokiem jest utworzenie publikacji definiującej, które obiekty danych zostaną replikowane dla subskrybentów.
Aby utworzyć publikację za pomocą SQL Server Studio zarządzania:
- W Eksploratorze obiektów rozwiń Replikacja teczka.
- Kliknij prawym przyciskiem myszy Publikacje lokalne na której: Nowa publikacja.
- Kreator nowej publikacjitarts; kliknij Następna na stronie powitalnej.
- Wybierz bazę danych, którą chcesz opublikować Baza publikacji strona. Automatycznie włącza publikację w wybranej bazie danych.
- Na Typ publikacji strona, wybierz typ replikacji: Publikacja migawkowa, Publikacja transakcyjna, Publikacja peer-to-peerlub Połącz publikację.
- Na Artykuły strona, rozwiń Tables węzeł i wybierz tabele, które mają zostać uwzględnione jako artykuły.
- Opcjonalnie rozszerz Procedury składowane, odwiedzajacylub inne typy obiektów, aby uwzględnić dodatkowe artykuły.
- Kliknij Właściwości artykułu aby skonfigurować filtrowanie i inne ustawienia specyficzne dla artykułu.
- Na Filtruj wiersze tabeli strona, dodaj filtry wierszy, jeśli to konieczne.
- Na Agent migawek wybierz, kiedy chcesz utworzyć migawkę: natychmiast, o określonej porze czy według harmonogramu.
- Na Bezpieczeństwo agenta strona, określ kontekst zabezpieczeń dla agenta migawek.
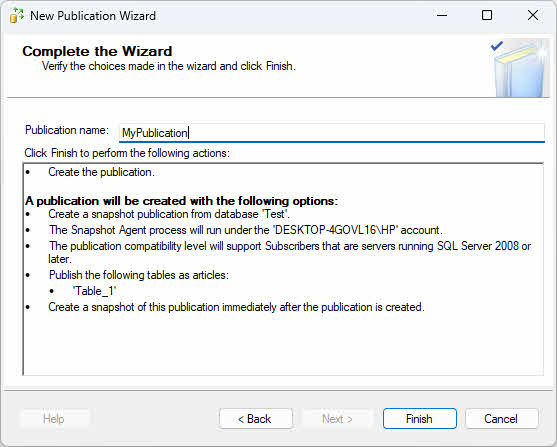
- Na Akcje kreatora strona, wybierz Utwórz publikację.
- Podaj nazwę publikacji i kliknij Zakończ.
4.4 Krok 3: Utwórz subskrypcję
Po utworzeniu publikacji kolejnym krokiem jest utworzenie subskrypcji łączących publikację z bazami danych subskrybentów.
Subskrypcje mogą być subskrypcjami push (zarządzanymi przez dystrybutora) lub pull (zarządzanymi przez subskrybenta). Kluczowe różnice polegają na miejscu utworzenia subskrypcji i wyborze lokalizacji agenta, co decyduje o działaniu subskrypcji (push lub pull).
Do subskrypcji push (zarządzane przez Dystrybutora):
- Na wydawca serwer, rozszerz Replikacja -> Publikacje lokalne.
- Kliknij publikację prawym przyciskiem myszy i wybierz Nowe subskrypcje.
Do subskrypcji Pull (zarządzane przez Abonenta):
- Na abonent serwer, rozszerz Replikacja, kliknij prawym przyciskiem myszy Subskrypcje lokalnei wybierz Nowe subskrypcje.
- Na Publikacja strony, kliknij Znajdź SQL Server wydawca i połączyć się z serwerem wydawcy.
Typowe kroki kreatora dla obu typów subskrypcji:
- W Kreatorze nowej subskrypcji kliknij Następna na stronie powitalnej.
- Wybierz publikację i kliknij Następna.
- Na Lokalizacja agenta dystrybucyjnego strona, wybierz lokalizację agenta:
- Subskrypcja push: Wybierz „Uruchom wszystkich agentów u dystrybutora” – dystrybutor prześle zmiany subskrybentom.
- Subskrypcja pull: Wybierz „Uruchom każdego agenta u jego subskrybenta” – każdy subskrybent pobierze zmiany od dystrybutora.
- Na abonenci strona, wybierz istniejące serwery abonenckie lub kliknij Dodaj Abonenta aby dodać nowe.
- Dla każdego subskrybenta wybierz bazę danych docelową lub utwórz nową bazę danych. Uwaga: Baza danych subskrypcji musi być inna niż baza danych wydawcy, nawet jeśli korzystają z tej samej bazy danych. SQL Server instancja.
- Na Bezpieczeństwo agenta dystrybucyjnego Na stronie kliknij przycisk właściwości dla każdej subskrypcji, aby skonfigurować kontekst zabezpieczeń.
- Na Harmonogram synchronizacji wybierz synchronizację ciągłą lub zaplanowaną.
- Na Zainicjuj subskrypcje strona, wybierz Natychmiast zainicjować podczas kończenia pracy kreatora lub Przy pierwszej synchronizacji.
- Przejrzyj działania kreatora i kliknij Zakończ.
5. Monitorowanie i zarządzanie SQL Server Replikacja
5.1 Monitorowanie replikacji za pomocą Monitora replikacji
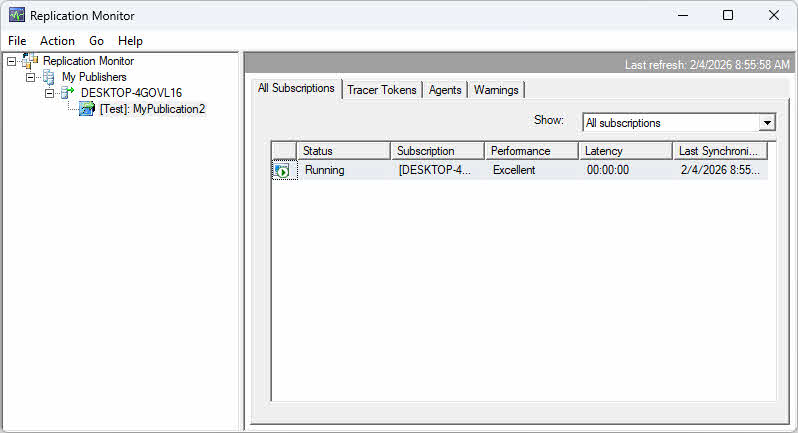
Aby uruchomić Monitor replikacji:
- In SQL Server Management Studio, rozwiń Replikacja w Eksploratorze obiektów.
- Kliknij prawym przyciskiem myszy Replikacja na której: Uruchom Monitor Replikacji.
- Jeżeli nie zarejestrowano żadnego wydawcy, kliknij Dodaj wydawcę w lewym okienku.
- Dodaj Dodaj SQL Server wydawca i połączyć się z serwerem wydawcy.
- Wydawca jest widoczny w lewym panelu z rozwijalnymi węzłami dla publikacji i subskrypcji.
5.2 Monitorowanie wydajności
5.2.1 Opóźnienie monitora
Opóźnienie replikacji to opóźnienie między wprowadzeniem zmiany u wydawcy a jej wprowadzeniem u subskrybenta. Monitoruj opóźnienie, aby zapewnić aktualność danych zgodnie z wymaganiami biznesowymi.
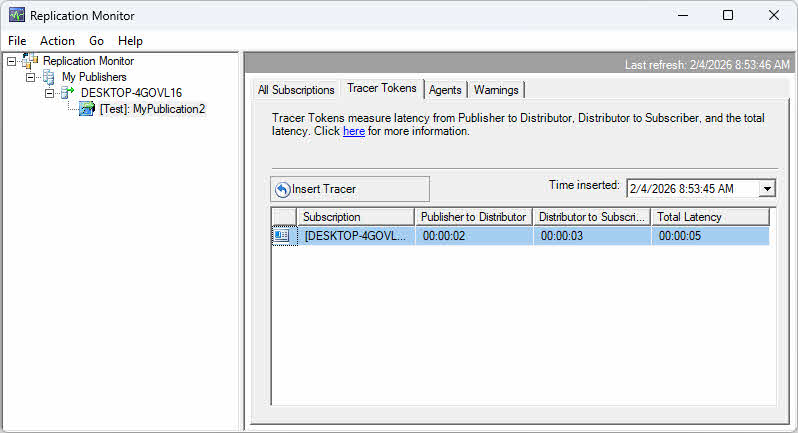
Użyj Monitora replikacji, aby wyświetlić metryki opóźnień na karcie Wszystkie subskrypcje. Kolumna „Opóźnienie” pokazuje średnie opóźnienie w sekundach. W przypadku replikacji transakcyjnej tokeny śledzące zapewniają precyzyjne pomiary opóźnień poprzez wstawianie transakcji znacznikowych, które są śledzone w procesie replikacji.
Aby użyć tokenów śledzących:
- W Monitorze replikacji wybierz publikację transakcyjną.
- Kliknij Tokeny śledzące .
- Kliknij Wstaw Tracer wstrzyknąć transakcję znacznikową.
- Monitoruj token w trakcie jego podróży od wydawcy do dystrybutora i subskrybenta.
- Sprawdź czas potrzebny na zidentyfikowanie wąskich gardeł w każdym segmencie.
5.2.2 Monitoruj przepustowość
Przepustowość mierzy ilość danych replikowanych w czasie, zazwyczaj wyrażaną w transakcjach na sekundę lub poleceniach na sekundę. Monitoruj przepustowość, aby upewnić się, że replikacja nadąża za aktywnością wydawcy.
Chociaż Monitor Replikacji zapewnia podstawowy stan synchronizacji, szybkość dostarczania i szczegółowe metryki przepustowości nie są widoczne w interfejsie graficznym. Aby monitorować przepustowość, użyj zapytań T-SQL do bazy danych dystrybucji:
USE distribution
GO
-- Direct join to avoid subquery
SELECT TOP 20
h.time AS [Time],
a.name AS [Agent Name],
h.runstatus AS [Status],
h.delivered_transactions AS [Delivered Transactions],
h.delivered_commands AS [Delivered Commands],
h.delivery_rate AS [Delivery Rate (commands/sec)],
h.delivery_latency AS [Delivery Latency (ms)],
h.comments AS [Comments]
FROM MSdistribution_history h
JOIN MSdistribution_agents a ON h.agent_id = a.id
WHERE a.name LIKE '%MyPublication2%'
AND h.runstatus IN (2, 3, 4, 6)
ORDER BY h.time DESC
GO
Kody statusu: 1 = Start, 2 = W toku, 3 = Powodzenie, 4 = Bezczynność, 5 = Ponów próbę, 6 = Niepowodzenie. Porównaj wskaźnik dostarczalności z wskaźnikami transakcji wydawcy, aby zidentyfikować sytuacje, w których replikacja jest opóźniona. Liczniki wydajności w Monitor wydajności systemu Windows zapewnia dodatkowe metryki przepustowości dla każdego agenta replikacji.
5.2.3 Identyfikacja wąskich gardeł
Wąskie gardła replikacji mogą występować w wielu punktach topologii. U wydawcy nadmierny czas generowania migawek lub opóźnienia agenta odczytu logów mogą wskazywać na ograniczenia zasobów. Monitoruj procesor, pamięć i operacje wejścia/wyjścia na dysku u wydawcy podczas replikacji.
U dystrybutora sprawdź, czy w bazie danych dystrybucji nie kumulują się transakcje. Duża liczba nierozdystrybuowanych poleceń wskazuje, że dystrybutor nie nadąża z dostawami. Monitoruj zasoby serwera dystrybutora i rozważ użycie dedykowanego, zdalnego dystrybutora w przypadku scenariuszy o dużym wolumenie.
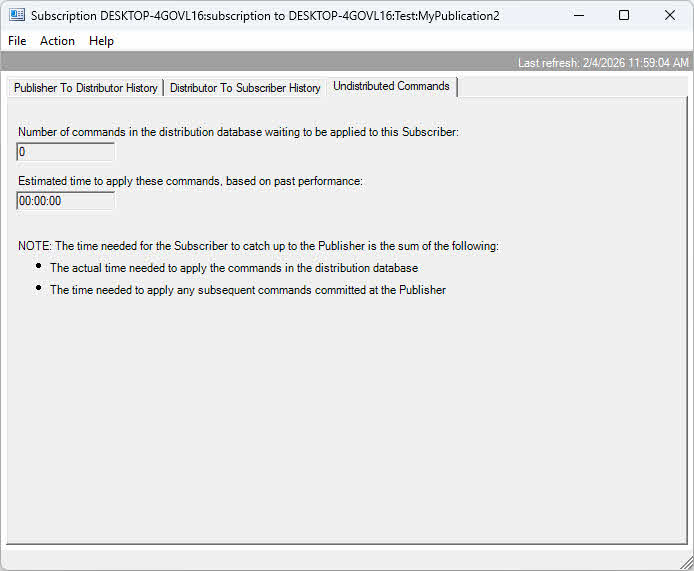
Po stronie subskrybenta powolne wprowadzanie zmian może wynikać z niewystarczających zasobów, brakujących indeksów lub ograniczeń spowalniających operacje wstawiania. Monitoruj wykorzystanie zasobów subskrybenta i wydajność zapytań, gdy agent dystrybucji jest uruchomiony. Ograniczenia przepustowości sieci między komponentami również powodują wąskie gardła, szczególnie w przypadku dużych wolumenów danych.
5.3 Zarządzanie agentami replikacji
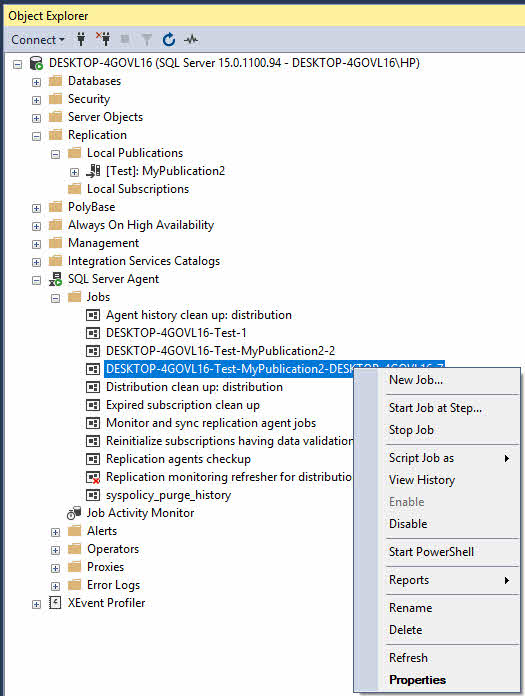
5.3.1 StarAgenci t i Stop
Do S.tarlub zatrzymaj agenta replikacji:
- In SQL Server Management Studio, rozwiń SQL Server Agent -> Oferty pracy.
- Zlokalizuj zadanie agenta replikacji (nazwy zwykle zawierają informacje o publikacji i subskrybencie).
- Kliknij prawym przyciskiem myszy zadanie i wybierz StarPraca t or Zatrzymaj pracę.
5.3.2 Konfigurowanie profili agentów
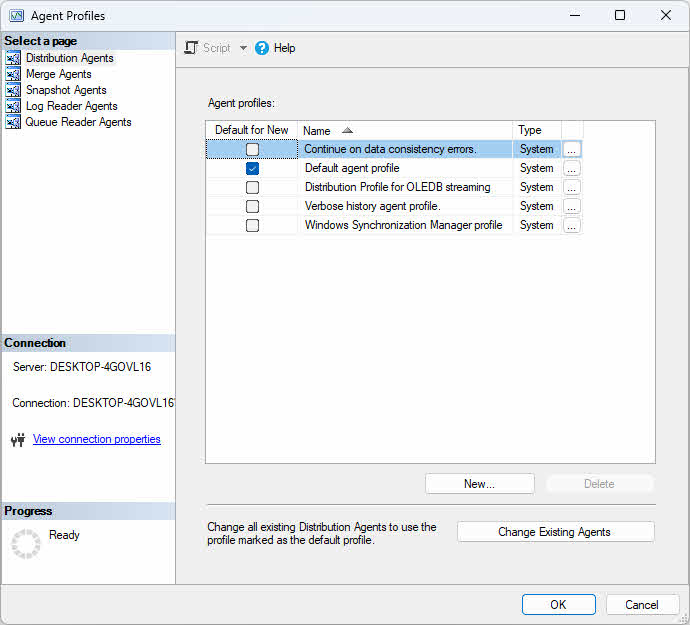
Profile agentów zawierają zestawy parametrów, które kontrolują zachowanie agenta. SQL Server zapewnia domyślne profile zoptymalizowane pod kątem typowych scenariuszy, a także umożliwia tworzenie niestandardowych profili dla określonych potrzeb.
Aby zmodyfikować profile agentów:
- W Eksploratorze obiektów rozwiń Replikacja.
- Kliknij prawym przyciskiem myszy Replikacja na której: Właściwości dystrybutora.
- Kliknij Ustawienia domyślne profilu .
- Wybierz typ agenta (Migawka, Czytnik dziennika, Dystrybucja lub Scalenie) z listy rozwijanej.
- Wybierz profil i kliknij Właściwości aby wyświetlić wartości parametrów.
- Kliknij Nowy profil aby utworzyć nowy profil na podstawie już istniejącego.
- W razie potrzeby zmodyfikuj parametry i kliknij OK.
Aby zastosować profil do agenta, edytuj właściwości subskrypcji i wybierz żądany profil z listy rozwijanej Profil agenta.
5.3.3 Parametry i ustawienia agenta
Parametry agenta precyzyjnie dostosowują wydajność i zachowanie. Kluczowe parametry agenta dystrybucji to CommitBatchSize (liczba transakcji zastosowanych na zatwierdzenie), CommitBatchThreshold (liczba poleceń przed zatwierdzeniem), SubscriptionStreams (połączenia równoległe dla szybszego dostarczania) oraz QueryTimeout (limit czasu dla poleceń).
W przypadku agenta Log Reader ważne parametry to ReadBatchSize (liczba transakcji odczytanych na skanowanie), ReadBatchThreshold (liczba poleceń przed dostarczeniem) oraz PollingInterval (opóźnienie między skanami dziennika). Dostosuj te parametry w zależności od wolumenu transakcji i wymagań dotyczących opóźnienia.
5.4 Zagadnienia dotyczące tworzenia kopii zapasowych i przywracania danych
Tworzenie kopii zapasowych baz danych objętych replikacją wymaga szczególnych rozwiązań. W przypadku bazy danych wydawcy, regularne tworzenie pełnych kopii zapasowych i kopii dziennika transakcji jest niezbędne. Oznacz kopię zapasową bazy danych do obsługi replikacji, używając opcji WITH REPLICATION podczas tworzenia kopii zapasowych baz danych w replikacji transakcyjnej. Regularnie twórz kopię zapasową bazy danych dystrybucji, aby chronić konfigurację replikacji.
Przywracając bazę danych wydawcy na ten sam serwer o tej samej nazwie, należy użyć opcji WITH KEEP_REPLICATION, aby zachować stan replikacji. Ta opcja gwarantuje, że transakcje, które nie zostały jeszcze przetworzone przez agenta odczytu dziennika, pozostaną oznaczone do replikacji, umożliwiając automatyczne kontynuowanie replikacji bez ponownej inicjalizacji subskrypcji.
W przypadku odzyskiwania danych po awarii, gdy kopie zapasowe są niedostępne, uszkodzone lub pliki bazy danych są uszkodzone, konieczne może być skorzystanie ze specjalistycznych narzędzi do odzyskiwania danych. DataNumen SQL Recovery umożliwia wyodrębnienie danych z uszkodzonych lub niedostępnych plików MDF i NDF, stanowiąc ostateczność w przypadku, gdy standardowe procedury przywracania danych zawiodą.
Więcej informacji na temat SQL Server kopia zapasowa, zobacz nasze obszerny przewodnik.
6. Często zadawane pytania (FAQ)
P: Jaka jest różnica między replikacją migawkową a replikacją transakcyjną?
A: Replikacja migawkowa tworzy kompletną kopię danych w określonym momencie i stosuje ją do subskrybenta, co jest przydatne w przypadku danych zmieniających się rzadko. Replikacja transakcyjnatartworzy migawkę początkową, a następnie stale replikuje poszczególne transakcje w miarę ich występowania, zapewniając synchronizację niemal w czasie rzeczywistym w przypadku często zmieniających się danych.
P: Czy mogę replikować między różnymi SQL Server wersje?
Odp .: Tak, SQL Server Replikacja obsługuje kompatybilność wersji w ograniczonym zakresie. Wersja dystrybutora musi być co najmniej taka sama jak wersja wydawcy, a subskrybent może znajdować się w odległości do dwóch wersji od wydawcy. Na przykład, jeśli wydawca to SQL Server 2016, abonent może być SQL Server 2012, 2014, 2016, 2017 lub 2019.
P: Jak radzić sobie z konfliktami podczas replikacji scalającej?
A: Replikacja scalająca oferuje wbudowane mechanizmy wykrywania i rozwiązywania konfliktów. Rozwiązywanie konfliktów można skonfigurować na poziomie artykułu, wybierając spośród wbudowanych rozwiązań lub implementując własne rozwiązania. Konflikty są zazwyczaj rozwiązywane za pomocą metod opartych na priorytetach lub znacznikach czasu, z możliwością rejestrowania konfliktów w celu ręcznego przeglądu.
P: Jaki wpływ na wydajność ma replikacja?
A: Replikacja wpływa na wydajność na kilka sposobów: wydawca ponosi obciążenie związane ze śledzeniem zmian i generowaniem migawek, dystrybutor wykorzystuje zasoby do przechowywania i przekazywania transakcji, a przepustowość sieci jest zużywana podczas przesyłania danych. Wpływ ten różni się w zależności od typu replikacji – replikacja migawek powoduje okresowe, intensywne obciążenia, a replikacja transakcyjna utrzymuje bardziej spójne, ale ciągłe obciążenie.
P: Jak zabezpieczyć topologię replikacji?
A: Zabezpiecz swoją topologię replikacji, wdrażając kilka najlepszych praktyk: użyj uwierzytelniania systemu Windows lub silnego uwierzytelniania SQL Server uwierzytelnianie, szyfrowanie połączeń za pomocą protokołu TLS, zabezpieczenie folderu migawki odpowiednimi zabezpieczeniami NTFS uprawnienia, skonfiguruj listę dostępu do publikacji (PAL) w celu kontrolowania dostępu, użyj oddzielnych kont usługowych z minimalnymi wymaganymi uprawnieniami dla każdego agenta replikacji i regularnie przeprowadzaj audyt ustawień zabezpieczeń replikacji.
P: Czy mogę replikować do bazy danych Azure SQL?
Odp.: Tak, replikację do bazy danych Azure SQL można wykonać za pomocą replikacji transakcyjnej z lokalnym serwerem SQL Server lub Azure SQL Managed Instance jako wydawca i dystrybutor. Baza danych Azure SQL może pełnić rolę subskrybenta, ale nie wydawcy ani dystrybutora. Replikacja scalająca i replikacja peer-to-peer nie są obsługiwane w usłudze Azure SQL Database.
P: Jak monitorować opóźnienia replikacji?
A: Monitoruj opóźnienie replikacji za pomocą Monitora replikacji w SQL Server Management Studio, które wyświetla metryki opóźnień dla każdej subskrypcji. Można również wykonywać zapytania do tabel baz danych dystrybucji, takich jak MSdistribution_history i MSrepl_commands, korzystać z liczników wydajności specyficznych dla agentów replikacji lub konfigurować alerty na podstawie progów opóźnień, aby proaktywnie wykrywać i rozwiązywać problemy z opóźnieniami synchronizacji.
P: Co się dzieje, gdy subskrybent jest offline?
O: Gdy abonent jest offline, zachowanie zależy od typu replikacji. W przypadku replikacji transakcyjnej transakcje kumulują się w bazie danych dystrybucyjnej do momentu ponownego połączenia abonenta z siecią, po czym synchronizacja jest wznawiana. W przypadku replikacji scalającej zmiany są śledzone po obu stronach i scalane po przywróceniu połączenia. Ustawienie okresu przechowywania określa, jak długo dane są przechowywane, zanim będą musiały zostać ponownie zainicjowane.
P: Jak dodawać nowe artykuły do istniejącej publikacji?
A: Aby dodać nowe artykuły do istniejącej publikacji, użyj SQL Server Management Studio, aby zmodyfikować właściwości publikacji i wybrać dodatkowe obiekty, lub użyj procedury składowanej sp_addarticle. Po dodaniu artykułów wygeneruj nową migawkę i ponownie zainicjuj wszystkie subskrypcje, aby zapewnić subskrybentom dostęp do nowych artykułów. Niektóre zmiany mogą wymagać ponownej inicjalizacji subskrypcji, w zależności od ustawień publikacji.
P: Jak usunąć replikację z bazy danych?
A: Usuń replikację z bazy danych, najpierw usuwając wszystkie subskrypcje za pomocą sp_dropsubscription, następnie usuwając publikację za pomocą sp_droppublication, a na koniec wyłączając publikowanie w bazie danych za pomocą sp_replicationdboption. Jeśli serwer jest dystrybutorem, wyłącz dystrybucję za pomocą sp_dropdistributor. Zawsze wykonuj kopię zapasową baz danych przed usunięciem konfiguracji replikacji.
P: Jaka jest różnica między SQL Server Replikacja i grupy dostępności AlwaysOn?
A: Replikacja to rozwiązanie dystrybucji i integracji danych działające na poziomie obiektów, Grupy dostępności Always On jest rozwiązaniem zapewniającym wysoką dostępność i odzyskiwanie danych po awarii, które działa na poziomie bazy danych.
7. Wniosek
SQL Server Replikacja zapewnia solidne ramy do dystrybucji i synchronizacji danych w wielu bazach danych i lokalizacjach. Technologia ta obsługuje różne scenariusze poprzez różne typy replikacji.
Wybór odpowiedniej strategii replikacji zależy od konkretnych wymagań. Należy wziąć pod uwagę częstotliwość zmian danych, wymagania dotyczące opóźnień, konieczność aktualizacji danych przez abonentów, charakterystykę sieci oraz potrzeby autonomii abonenta. Replikacja migawkowa sprawdza się najlepiej w przypadku rzadko zmieniających się danych referencyjnych, gdzie opóźnienie nie jest krytyczne. Replikacja transakcyjna sprawdza się w scenariuszach o dużej objętości, wymagających niskich opóźnień i przede wszystkim jednokierunkowego przepływu danych.
Wybierz replikację scalającą, gdy subskrybenci potrzebują autonomicznego działania z możliwością pracy w trybie offline i synchronizacją dwukierunkową. Wdrażaj replikację peer-to-peer, aby równoważyć obciążenie operacji odczytu na wielu aktywnych węzłach, zapewniając spójność niemal w czasie rzeczywistym. Rozważ podejścia hybrydowe, łączące wiele typów replikacji w przypadku złożonych scenariuszy o zróżnicowanych wymaganiach.
Referencje
- Oficjalny dokument firmy Microsoft: SQL Server Replikacja
- Oficjalny dokument firmy Microsoft: Typy replikacji
- Oficjalny dokument firmy Microsoft: Replikacja transakcyjna typu peer-to-peer
O autorze
Yuan Sheng jest starszym administratorem baz danych (DBA) z ponad 10-letnim doświadczeniem w SQL Server środowiskach i zarządzaniu bazami danych przedsiębiorstw. Z powodzeniem rozwiązał setki scenariuszy odzyskiwania baz danych w firmach z branży usług finansowych, opieki zdrowotnej i produkcji.
Yuan specjalizuje się w SQL Server Odzyskiwanie baz danych, rozwiązania wysokiej dostępności i optymalizacja wydajności. Jego bogate doświadczenie praktyczne obejmuje zarządzanie wieloterabajtowymi bazami danych, wdrażanie grup Always On Availability Groups oraz opracowywanie zautomatyzowanych strategii tworzenia kopii zapasowych i odzyskiwania danych dla systemów biznesowych o znaczeniu krytycznym.
Dzięki swojej wiedzy technicznej i praktycznemu podejściu Yuan skupia się na tworzeniu kompleksowych przewodników, które pomagają administratorom baz danych i specjalistom IT rozwiązywać złożone problemy SQL Server skutecznie stawia czoła wyzwaniom. Jest na bieżąco z najnowszymi SQL Server wydania i rozwijające się technologie baz danych firmy Microsoft, regularnie testując scenariusze odzyskiwania, aby mieć pewność, że jego zalecenia odzwierciedlają najlepsze praktyki stosowane w praktyce.
Masz pytania dot SQL Server Potrzebujesz pomocy w odzyskiwaniu danych lub dodatkowych wskazówek dotyczących rozwiązywania problemów z bazą danych? Yuan zaprasza opinie i sugestie w celu udoskonalenia tych zasobów technicznych.