1. Introduzione a SQL Server replicazione
1.1 Che cos'è SQL Server Replica?
SQL Server La replicazione è un insieme di tecnologie per copiare e distribuire dati e oggetti di database da un database all'altro, sincronizzandoli poi tra loro per mantenerne la coerenza. Questa funzionalità consente di creare e gestire più copie dei dati su server e posizioni diverse, garantendone la disponibilità e l'affidabilità.
1.2 Scopo e vantaggi della replicazione
SQL Server La replicazione soddisfa molteplici esigenze aziendali critiche e offre vantaggi significativi per la gestione del database e la distribuzione dei dati:
- Distribuzione dei dati tra le sedi: La replica consente di condividere i dati tra sedi regionali o sedi globali, migliorando l'efficienza operativa grazie all'accesso locale ai dati richiesti. Ciò riduce la latenza di rete e offre prestazioni migliori per gli utenti distribuiti geograficamente.
- Alta disponibilità e ripristino di emergenza: Mantenendo repliche di dati critici su più server, la replicazione fornisce ridondanza che protegge da guasti hardware e disastri. In caso di guasto del server primario, le copie replicate possono fungere da fonti di fallback, riducendo al minimo i tempi di inattività e la perdita di dati.
- Bilanciamento del carico e scalabilità: La replica distribuisce le operazioni di lettura su più server, evitando che un singolo server diventi un collo di bottiglia. Questo approccio migliora le prestazioni del sistema e consente all'infrastruttura di scalare orizzontalmente in base alla crescita dei dati e delle esigenze degli utenti.
- Rapporti e analisi in tempo reale: L'esternalizzazione delle query di reporting e analisi su server replicati riduce il carico sui database di produzione. Gli utenti possono eseguire query analitiche complesse su dati quasi in tempo reale senza influire sui sistemi operativi, garantendo prestazioni e aggiornamento dei dati.
- Integrazione e consolidamento dei dati: La replica facilita l'unione di dati provenienti da diverse fonti in un'unica vista consolidata. Questa funzionalità è particolarmente utile per le organizzazioni con più filiali che necessitano di aggregare i dati presso la sede centrale o per la creazione di data warehouse centralizzati da sistemi operativi distribuiti.
2. SQL Server Architettura e componenti di replicazione
SQL Server L'architettura di replicazione è composta da diversi componenti interconnessi che collaborano per distribuire e sincronizzare i dati nell'infrastruttura del database. Questa sezione esplora i componenti principali, inclusi editori, distributori, abbonati, pubblicazioni, articoli, abbonamenti e gli agenti che coordinano il flusso di dati tra di essi:
- Editore: Un editore è un SQL Server esempio che hostè uno o più database contenenti dati da replicare. Funge da fonte autorevole nella topologia di replica.
- Distributore: Un distributore è un SQL Server istanza che gestisce il flusso di dati tra editori e abbonati. L'istanza del distributore hostè il database di distribuzione, che memorizza i metadati di replicazione e le transazioni.
- Subscriber: Un abbonato è un SQL Server istanza che riceve e memorizza dati replicati dagli editori. Una singola istanza di abbonato può host più database di abbonati, ognuno dei quali riceve dati da pubblicazioni diverse.
- Pubblicazione: Una pubblicazione definisce quali dati verranno replicati e come verranno distribuiti agli abbonati. Raggruppa gli articoli correlati e stabilisce la metodologia di replicazione applicabile a tutti gli oggetti contenuti.
- Articolo: Un articolo è l'elemento fondamentale della replicazione e rappresenta un singolo oggetto di database che verrà distribuito agli abbonati.
- Sottoscrizione: Un abbonamento stabilisce la relazione tra una pubblicazione e un abbonato, definendo come e quando i dati vengono consegnati al database di destinazione.
- agenti: Gli agenti sono processi specializzati che eseguono il lavoro effettivo di spostamento e sincronizzazione dei dati tra i componenti di replicazione.

3. Tipi di SQL Server replicazione
SQL Server offre diverse tipologie di replica, ciascuna progettata per specifici scenari di distribuzione dei dati e requisiti aziendali. Comprendere le caratteristiche, i vantaggi e i limiti di ciascuna tipologia è essenziale per scegliere l'approccio più adatto al proprio ambiente.
3.1 Replica snapshot
La replica snapshot acquisisce uno snapshot dei dati da pubblicare in un momento specifico, quindi distribuisce la copia completa ed esatta agli abbonati. Non monitora le modifiche successive fino alla generazione dello snapshot successivo. La replica snapshot è la forma più semplice di replica, il che la rende adatta a scenari in cui i dati cambiano raramente o in cui è accettabile avere dati leggermente obsoleti.
I casi d'uso più comuni includono la distribuzione di dati di riferimento, come listini prezzi o tassi di cambio, che si aggiornano periodicamente, la fornitura di set di dati iniziali per i data warehouse e scenari in cui un aggiornamento completo dei dati è preferibile al monitoraggio delle singole modifiche. Ad esempio, un'azienda potrebbe utilizzare la replica snapshot per distribuire cataloghi prodotti aggiornati alle filiali una volta al giorno.
I principali vantaggi della replica snapshot sono la semplicità, i bassi requisiti di manutenzione e la possibilità di replicare i dati senza chiavi primarie. Tuttavia, presenta svantaggi significativi, tra cui un impatto elevato durante la generazione degli snapshot a causa dei blocchi delle tabelle, un'elevata latenza tra gli aggiornamenti e l'inefficienza per set di dati di grandi dimensioni o dati che cambiano frequentemente. Qualsiasi modifica apportata agli abbonati è...ost quando viene applicato lo snapshot successivo.
3.2 Replica transazionale
La replica transazionale trasmette le modifiche dall'editore agli abbonati quasi in tempo reale, replicando le singole transazioni man mano che si verificano. Inizia con uno snapshot iniziale per stabilire la baseline, quindi monitora costantemente il registro delle transazioni per rilevare eventuali modifiche agli articoli pubblicati e le trasmette agli abbonati in modo incrementale.
La replica transazionale è ideale per scenari server-to-server che richiedono elevata produttività e bassa latenza. I casi d'uso più comuni includono il miglioramento della scalabilità e della disponibilità tramite l'allocazione delle operazioni di lettura sui server degli abbonati, il supporto del data warehousing e del reporting con dati quasi in tempo reale, l'integrazione dei dati provenienti da più siti in un'unica posizione centrale e l'allocazione dell'elaborazione batch su server dedicati. Ad esempio, una piattaforma di e-commerce potrebbe utilizzare la replica transazionale per mantenere sincronizzati i dati di inventario tra i database regionali.
I vantaggi della replica transazionale includono la consegna dei dati a bassa latenza, l'elevata produttività per grandi volumi di transazioni e la possibilità di apportare modifiche non replicate presso gli abbonati. Gli svantaggi includono una maggiore complessità rispetto alla replica snapshot, la necessità di chiavi primarie sulle tabelle replicate e la possibilità che la replica si interrompa in caso di conflitti, come violazioni delle chiavi primarie presso gli abbonati.
3.3 Replicazione di unione
La replica tramite merge è specificamente progettata per ambienti in cui gli abbonati devono lavorare offline o con connettività intermittente, per poi sincronizzare le modifiche quando la connessione è disponibile. Questo tipo di replica consente di modificare i dati in modo indipendente sia presso l'editore che presso gli abbonati, monitorando le modifiche tramite trigger e tabelle di metadati e unendo automaticamente le modifiche durante la sincronizzazione.
La replicazione tramite merge è progettata per applicazioni mobili e ambienti server distribuiti in cui si verificano modifiche autonome. I casi d'uso includono l'automazione della forza vendita, in cui gli utenti mobili lavorano offline e si sincronizzano in un secondo momento, sistemi POS che operano in modo indipendente e consolidano periodicamente i dati, e applicazioni distribuite in cui più sedi devono aggiornare i dati condivisi. Ad esempio, una catena di vendita al dettaglio potrebbe utilizzare la replicazione tramite merge in modo che ogni punto vendita possa gestire l'inventario locale sincronizzandosi con il sistema di magazzino centrale.
I vantaggi della replica tramite merge includono il supporto per abbonati autonomi che possono apportare modifiche, la tolleranza per la connettività di rete intermittente e la risoluzione flessibile dei conflitti. Gli svantaggi includono una maggiore complessità di configurazione e manutenzione, un sovraccarico di prestazioni dovuto al tracciamento di metadati e trigger, l'aggiunta di colonne uniqueidentifier alle tabelle e la possibilità di conflitti che richiedono gestione e risoluzione.
3.4 Replica peer-to-peer
La replica peer-to-peer si basa sulla replica transazionale e consente a più istanze server (tre o più nodi) di agire come peer uguali, con ciascun nodo che funge contemporaneamente da publisher e subscriber. In questa topologia, tutti i nodi mantengono copie identiche dei dati e possono gestire sia le operazioni di lettura che di scrittura, fornendo un ambiente multi-master realmente distribuito.
La replica peer-to-peer è adatta per applicazioni che richiedono scale-out delle operazioni di lettura e alta disponibilità. I casi d'uso includono applicazioni web che distribuiscono query di catalogo su più nodi mantenendo dati coerenti, scenari che richiedono manutenzione o aggiornamenti senza tempi di inattività, disconnettendo i nodi singolarmente, e applicazioni globali con data center in diverse regioni. Ad esempio, un'organizzazione di supporto software a livello mondiale potrebbe utilizzare la replica peer-to-peer tra uffici con fusi orari diversi, in modo che ogni sede abbia accesso locale ai dati aggiornati.
I vantaggi della replica peer-to-peer includono prestazioni di lettura migliorate grazie alla scalabilità orizzontale, maggiore disponibilità con più nodi attivi e coerenza dei dati quasi in tempo reale. Gli svantaggi includono la necessità di un'edizione Enterprise, la complessità nella gestione di topologie multi-nodo, la necessità di uno schema e dati identici su tutti i nodi e il potenziale rischio di conflitti quando le operazioni di scrittura non sono correttamente partizionate.
3.5 Replicazione bidirezionale
La replica bidirezionale è una topologia di replica transazionale specifica, progettata specificamente per ambienti a due server in cui entrambi i server devono scambiarsi modifiche. Ogni server pubblica dati e sottoscrive gli stessi dati dall'altro server, creando un semplice flusso di sincronizzazione bidirezionale. Sebbene la replica peer-to-peer possa supportare anche due nodi, la replica bidirezionale offre prestazioni migliori per questo specifico scenario.
La replica bidirezionale è adatta per scenari che richiedono due server attivi con dati sincronizzati, come configurazioni attivo-attivo per alta disponibilità o applicazioni distribuite geograficamente in cui ogni sito necessita di accesso in scrittura locale. La topologia richiede un'attenta progettazione dell'applicazione per partizionare gli aggiornamenti dei dati e prevenire i conflitti.
I vantaggi includono prestazioni ottimizzate per scenari a due server, configurazione più semplice rispetto alla replica peer-to-peer, sincronizzazione quasi in tempo reale e overhead inferiore rispetto alla replicazione merge. Gli svantaggi includono la limitazione a due soli server, la mancanza di una risoluzione dei conflitti integrata che richiede un'attenta progettazione dell'applicazione e la necessità di strategie di partizionamento adeguate per prevenire i conflitti.
3.6 Abbonamenti aggiornabili
Le sottoscrizioni aggiornabili estendono la replica transazionale per consentire ai sottoscrittori di apportare modifiche occasionali ai dati replicati, che poi vengono propagate al publisher e agli altri sottoscrittori. A differenza della replica di tipo merge o delle topologie peer-to-peer progettate per frequenti aggiornamenti bidirezionali, le sottoscrizioni aggiornabili sono pensate per scenari in cui il flusso di dati primario è unidirezionale (dal publisher ai sottoscrittori), ma i sottoscrittori occasionalmente necessitano di apportare correzioni o aggiornamenti.
Gli abbonamenti aggiornabili sono adatti per scenari in cui most Gli aggiornamenti vengono effettuati presso l'editore, ma occasionalmente sono necessari aggiornamenti presso gli abbonati, come gli uffici periferici che leggono principalmente i dati ma devono apportare correzioni o aggiornamenti locali. La topologia richiede un'attenta pianificazione per ridurre al minimo i conflitti e garantire la coerenza dei dati.
I principali vantaggi includono la possibilità di eseguire operazioni di scrittura limitate presso gli abbonati, mantenendo al contempo le caratteristiche prestazionali della replica transazionale. Gli svantaggi includono una maggiore complessità, la possibilità di conflitti che richiedono una risoluzione, un sovraccarico di prestazioni dovuto al protocollo di commit a due fasi in modalità di aggiornamento immediato e il requisito che tutte le tabelle replicate abbiano chiavi primarie.
3.7 Confronto tra diversi tipi di repliche
| Tipo di replica | Tempo di aggiornamento | Numero di editori | Tipo di viaggio | Usa scenari |
|---|---|---|---|---|
| Istantanea | Punto nel tempo | 1 | Una direzione (Editore → Abbonati) | Dati di riferimento che cambiano raramente (listini prezzi, tassi di cambio) |
| transazionale | Quasi in tempo reale | 1 | Una direzione (Editore → Abbonati) | Scenari ad alta produttività (inventario e-commerce, data warehousing, reporting) |
| Unire | Periodico (quando connesso) | 1 | Bidirezionale (Editore ↔ Abbonati) | Applicazioni mobili, lavoratori offline (automazione della forza vendita, servizi sul campo) |
| Peer to peer | Quasi in tempo reale | Multiplo (3 o più) | Bidirezionale (tutti i nodi) | Distribuzioni globali multi-datacenter (uffici in tutto il mondo con accesso locale in lettura-scrittura) |
| bidirezionale | Quasi in tempo reale | 2 | Bidirezionale (entrambi i server) | Configurazioni attive-attive con due data center (alta disponibilità a doppio sito) |
| Abbonamenti aggiornabili | Quasi in tempo reale | 1 | Principalmente unidirezionale (aggiornamenti inversi occasionali) | Filiali che leggono principalmente ma occasionalmente aggiornano (correzioni locali) |
4. Configurazione SQL Server replicazione
4.1 Prerequisiti e requisiti
4.1.1 Requisiti software
SQL Server la replicazione richiede compatibilità SQL Server versioni tra tutti i partecipanti alla topologia. La versione del distributore deve essere uguale o superiore alla versione del publisher e il subscriber può trovarsi entro due versioni dal publisher. Ad esempio, un SQL Server L'editore del 2016 può replicare SQL Server Abbonati del 2012, 2014, 2016, 2017 o 2019.
4.1.2 Requisiti di autorizzazione
La configurazione della replica richiede autorizzazioni specifiche a ogni livello. I membri del ruolo server fisso sysadmin possono eseguire tutte le attività di configurazione della replica. Per autorizzazioni più granulari, gli utenti devono essere membri del ruolo database db_owner per i database publisher e subscriber.
4.2 Passaggio 1: configurare la distribuzione
La configurazione della distribuzione è il primo passo per l'impostazione SQL Server replicazione.
Per configurare la distribuzione utilizzando SQL Server Studio di direzione:
- Connettiti al SQL Server esempio in SQL Server Studio di gestione.
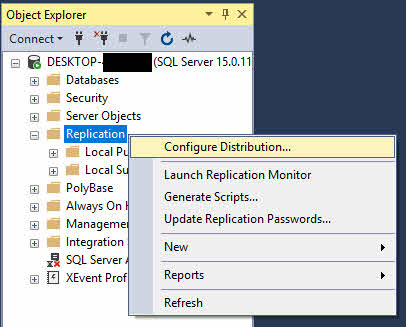
- In Esplora oggetti, fare clic con il pulsante destro del mouse su replicazione cartella e selezionare Configurare la distribuzione.

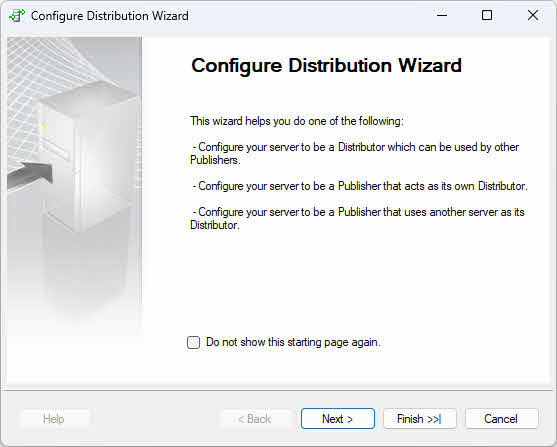
- Nella Configurazione guidata distribuzione, fare clic su Avanti nella pagina di benvenuto.

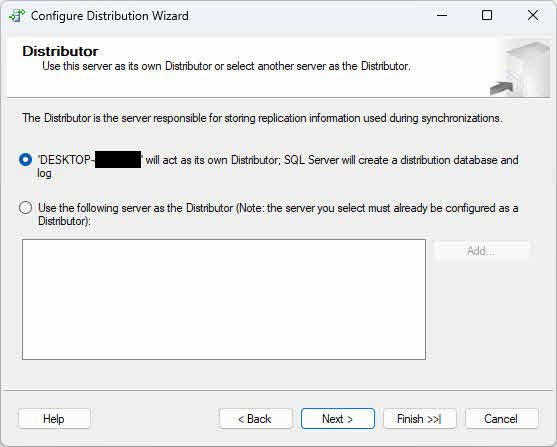
- Sulla Distributore pagina, scegli una delle seguenti opzioni in base ai requisiti della tua topologia:
- Distributore locale: Seleziona "ServerName agirà come il proprio distributore; SQL Server creerà un database di distribuzione e un registro" se si desidera che il publisher e il distributore vengano eseguiti sulla stessa istanza (l'istanza corrente). Questa configurazione è più semplice da impostare e adatta ad ambienti più piccoli o quando la latenza di rete tra il publisher e il distributore potrebbe causare problemi.
- Distributore remoto: Seleziona "Utilizza il seguente server come distributore" e fai clic Aggiungi Per specificare un server distributore remoto se si desidera delegare l'elaborazione della distribuzione a un'istanza separata. Questa configurazione migliora le prestazioni quando i volumi di replica sono elevati, distribuendo il carico di lavoro su più server. Sarà necessario fornire il nome del distributore remoto e specificare una password che l'editore utilizzerà per connettersi al distributore.
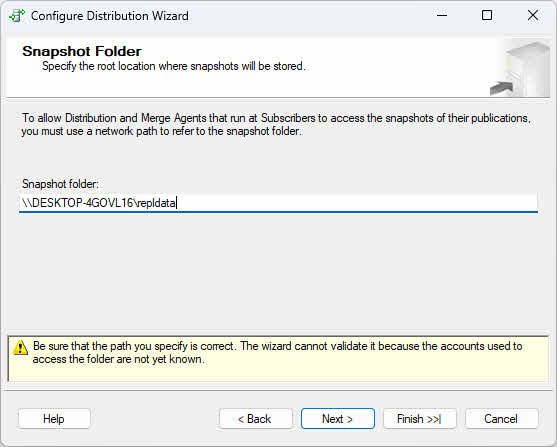
- Clicchi Avanti per specificare la posizione della cartella degli snapshot. Utilizzare un percorso UNC (ad esempio \\nomeserver\condivisione\cartella) anziché un percorso locale per garantire l'accessibilità in rete.
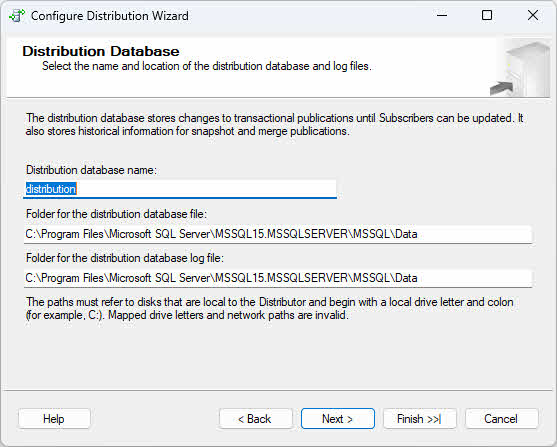
- Sulla Database di distribuzione pagina, accettare il nome predefinito del database di distribuzione (in genere "distribuzione") o specificare un nome personalizzato, quindi configurare le posizioni dei file di dati e di registro.
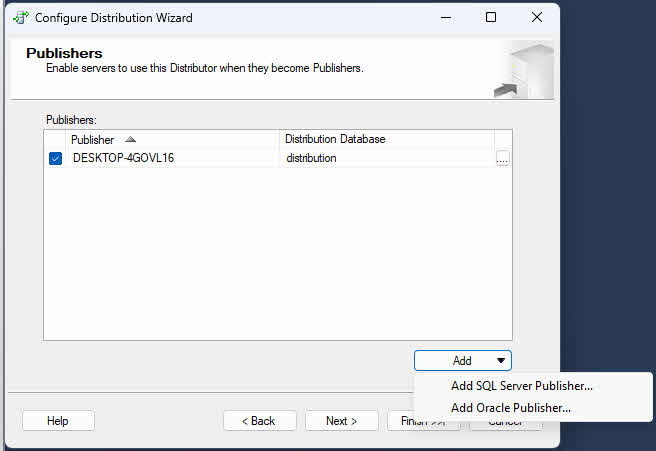
- Sulla Editori pagina, verificare che il server corrente sia abilitato come publisher. Se si configura il server corrente come distributore, è possibile aggiungere altri publisher che utilizzeranno questo distributore.

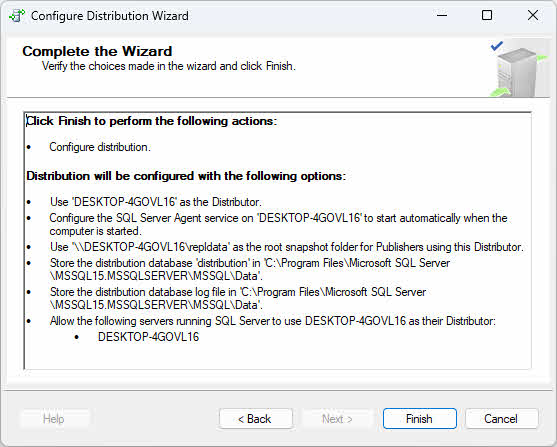
- Rivedi le azioni della procedura guidata e fai clic Finitura per configurare la distribuzione.
4.3 Passaggio 2: creare la pubblicazione
Dopo aver configurato la distribuzione, il passaggio successivo consiste nel creare una pubblicazione che definisca quali oggetti dati verranno replicati agli abbonati.
Per creare una pubblicazione utilizzando SQL Server Studio di direzione:
- In Esplora oggetti, espandere replicazione cartella.
- Fare clic con Pubblicazioni locali e seleziona Nuova pubblicazione.
- La procedura guidata per la nuova pubblicazionetarts; clicca Avanti nella pagina di benvenuto.
- Seleziona il database che vuoi pubblicare da Database delle pubblicazioni pagina. Ciò abilita automaticamente la pubblicazione sul database selezionato.
- Sulla Tipo di pubblicazione pagina, seleziona il tipo di replica: Pubblicazione istantanea, Pubblicazione transazionale, Pubblicazione peer-to-peer, o Unisci pubblicazione.
- Sulla Articoli pagina, espandere la tavoli nodo e seleziona le tabelle da includere come articoli.
- Espandi facoltativamente Procedura di archiviazione, Visualizzazionio altri tipi di oggetti per includere articoli aggiuntivi.
- Clicchi Proprietà dell'articolo per configurare il filtraggio o altre impostazioni specifiche dell'articolo.
- Sulla Filtra le righe della tabella pagina, aggiungere filtri di riga se necessario.
- Sulla Agente snapshot pagina, scegli quando creare lo snapshot: immediatamente, a un orario specifico o in base a una pianificazione.
- Sulla Sicurezza dell'agente pagina, specificare il contesto di sicurezza per l'agente snapshot.
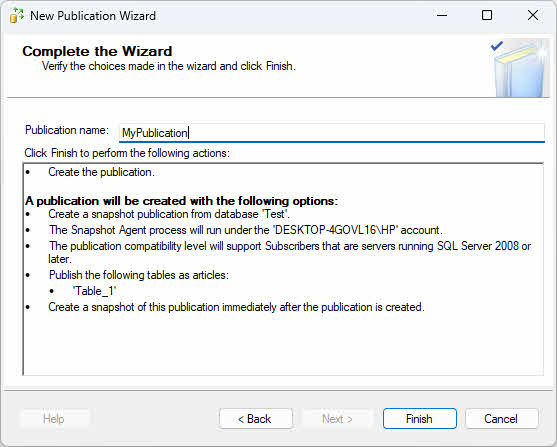
- Sulla Azioni della procedura guidata pagina, selezionare Crea la pubblicazione.
- Fornisci un nome di pubblicazione e fai clic Finitura.
4.4 Passaggio 3: creare un abbonamento
Dopo aver creato una pubblicazione, il passaggio successivo consiste nel creare abbonamenti che colleghino la pubblicazione ai database degli abbonati.
Gli abbonamenti possono essere push (gestiti dal distributore) o pull (gestiti dall'abbonato). Le differenze principali riguardano la posizione in cui si crea l'abbonamento e la posizione dell'agente selezionata, che determina l'azione dell'abbonamento (push o pull).
Per l'abbonamento Push (gestito dal Distributore):
- Sulla editore server, espandere replicazione -> Pubblicazioni locali.
- Fare clic con il pulsante destro del mouse sulla pubblicazione e selezionare Nuovi abbonamenti.
Per l'abbonamento Pull (gestito dall'Abbonato):
- Sulla abbonato server, espandere replicazione, tasto destro del mouse Abbonamenti localie selezionare Nuovi abbonamenti.
- Sulla Pubblicazione pagina, fare clic Trovate SQL Server Publisher e connettersi al server dell'editore.
Passaggi comuni della procedura guidata per entrambi i tipi di abbonamento:
- Nella procedura guidata Nuovo abbonamento, fare clic su Avanti nella pagina di benvenuto.
- Seleziona la pubblicazione e clicca Avanti.
- Sulla Posizione dell'agente di distribuzione pagina, scegli la posizione dell'agente:
- Abbonamento push: Seleziona "Esegui tutti gli agenti sul distributore": il distributore invierà le modifiche agli abbonati.
- Abbonamento pull: Seleziona "Esegui ogni agente sul suo abbonato": ogni abbonato estrarrà le modifiche dal distributore.
- Sulla Iscritti pagina, seleziona i server degli abbonati esistenti o fai clic Aggiungere Subscriber per aggiungerne di nuovi.
- Per ogni abbonato, seleziona il database di destinazione o creane uno nuovo. Attenzione: Il database degli abbonamenti deve essere diverso dal database dell'editore, anche se si utilizza lo stesso SQL Server esempio.
- Sulla Sicurezza dell'agente di distribuzione pagina, fare clic sul pulsante delle proprietà per ogni abbonamento per configurare il contesto di sicurezza.
- Sulla Programma di sincronizzazione pagina, scegliere la sincronizzazione continua o la sincronizzazione programmata.
- Sulla Inizializza gli abbonamenti pagina, selezionare Subito per inizializzare durante il completamento della procedura guidata o Alla prima sincronizzazione.
- Rivedi le azioni della procedura guidata e fai clic Finitura.
5. Monitoraggio e gestione SQL Server replicazione
5.1 Monitoraggio della replica con Replication Monitor
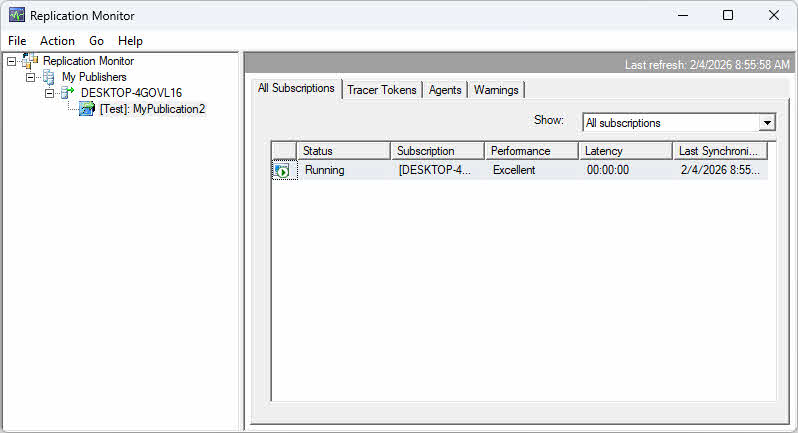
Per avviare Replication Monitor:
- In SQL Server Management Studio, espandi replicazione in Esplora oggetti.
- Fare clic con replicazione e seleziona Avvia Replication Monitor.
- Se non è registrato alcun editore, fare clic su Aggiungi editore nel riquadro di sinistra.
- Scegli Aggiungi SQL Server Publisher e connettersi al server dell'editore.
- L'editore appare nel riquadro di sinistra con nodi espandibili per pubblicazioni e abbonamenti.
5.2 Monitoraggio delle prestazioni
5.2.1 Monitorare la latenza
La latenza di replicazione è il ritardo temporale tra una modifica apportata al publisher e l'applicazione della stessa al subscriber. Monitorare la latenza per garantire che l'aggiornamento dei dati soddisfi i requisiti aziendali.
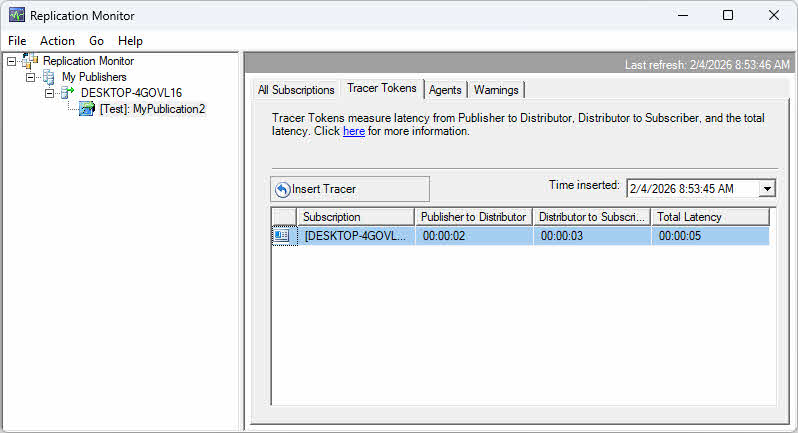
Utilizza Replication Monitor per visualizzare le metriche di latenza nella scheda "Tutti gli abbonamenti". La colonna "Latenza" mostra la latenza media in secondi. Per la replica transazionale, i token di tracciamento forniscono misurazioni precise della latenza inserendo transazioni marcatrici che vengono tracciate attraverso la pipeline di replica.
Per utilizzare i token di tracciamento:
- In Replication Monitor, selezionare una pubblicazione transazionale.
- Clicca su Gettoni Tracer scheda.
- Clicchi Inserisci Tracciante per iniettare una transazione marker.
- Monitora il token durante il suo passaggio dall'editore al distributore all'abbonato.
- Visualizza il tempo impiegato da ciascun segmento per identificare i colli di bottiglia.
5.2.2 Monitorare la produttività
La produttività misura il volume di dati replicati nel tempo, in genere espresso in transazioni al secondo o comandi al secondo. Monitorare la produttività per garantire che la replicazione possa tenere il passo con l'attività dell'editore.
Sebbene Replication Monitor fornisca informazioni di base sullo stato della sincronizzazione, la velocità di distribuzione e le metriche dettagliate sulla produttività non sono visibili nell'interfaccia utente grafica. Utilizzare query T-SQL sul database di distribuzione per monitorare la produttività:
USE distribution
GO
-- Direct join to avoid subquery
SELECT TOP 20
h.time AS [Time],
a.name AS [Agent Name],
h.runstatus AS [Status],
h.delivered_transactions AS [Delivered Transactions],
h.delivered_commands AS [Delivered Commands],
h.delivery_rate AS [Delivery Rate (commands/sec)],
h.delivery_latency AS [Delivery Latency (ms)],
h.comments AS [Comments]
FROM MSdistribution_history h
JOIN MSdistribution_agents a ON h.agent_id = a.id
WHERE a.name LIKE '%MyPublication2%'
AND h.runstatus IN (2, 3, 4, 6)
ORDER BY h.time DESC
GO
Codici di stato: 1 = Start, 2 = In corso, 3 = Riuscito, 4 = Inattivo, 5 = Riprova, 6 = Fallito. Confronta la velocità di consegna con le velocità di transazione dell'editore per identificare le situazioni in cui la replica è in ritardo. Contatori delle prestazioni in Monitoraggio delle prestazioni di Windows fornire metriche di produttività aggiuntive per ciascun agente di replicazione.
5.2.3 Identificare i colli di bottiglia
I colli di bottiglia della replica possono verificarsi in più punti della topologia. A livello di publisher, tempi di generazione degli snapshot eccessivi o ritardi del Log Reader Agent possono indicare vincoli di risorse. Monitorare CPU, memoria e I/O su disco sul publisher durante le attività di replica.
Presso il distributore, verificare l'accumulo di transazioni nel database di distribuzione. Un numero elevato di comandi non distribuiti indica che il distributore non riesce a tenere il passo con la consegna. Monitorare le risorse del server del distributore e valutare l'utilizzo di un distributore remoto dedicato per scenari ad alto volume.
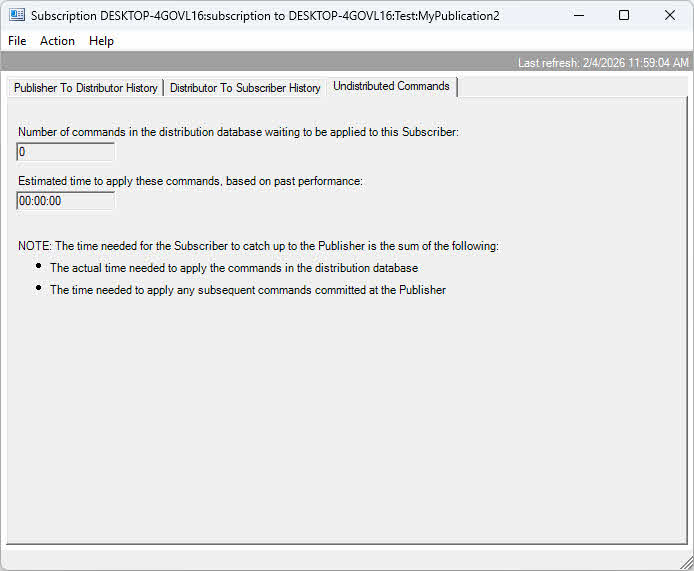
A livello di sottoscrittore, l'applicazione lenta delle modifiche può essere causata da risorse inadeguate, indici mancanti o vincoli che rallentano le operazioni di inserimento. Monitorare l'utilizzo delle risorse del sottoscrittore e le prestazioni delle query quando l'agente di distribuzione è in esecuzione. Anche le limitazioni della larghezza di banda di rete tra i componenti causano colli di bottiglia, in particolare per grandi volumi di dati.
5.3 Gestione degli agenti di replicazione
5.3.1 Start e agenti di arresto
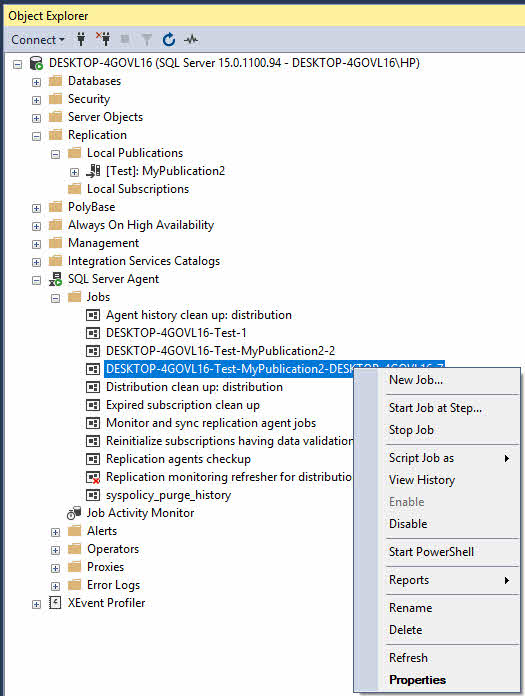
A staro interrompere un agente di replicazione:
- In SQL Server Management Studio, espandi SQL Server Agente -> Offerte di lavoro.
- Individuare il processo dell'agente di replicazione (i nomi in genere includono le informazioni sulla pubblicazione e sull'abbonato).
- Fare clic con il pulsante destro del mouse sul lavoro e selezionare Start Lavoro or Interrompi lavoro.
5.3.2 Configurare i profili degli agenti
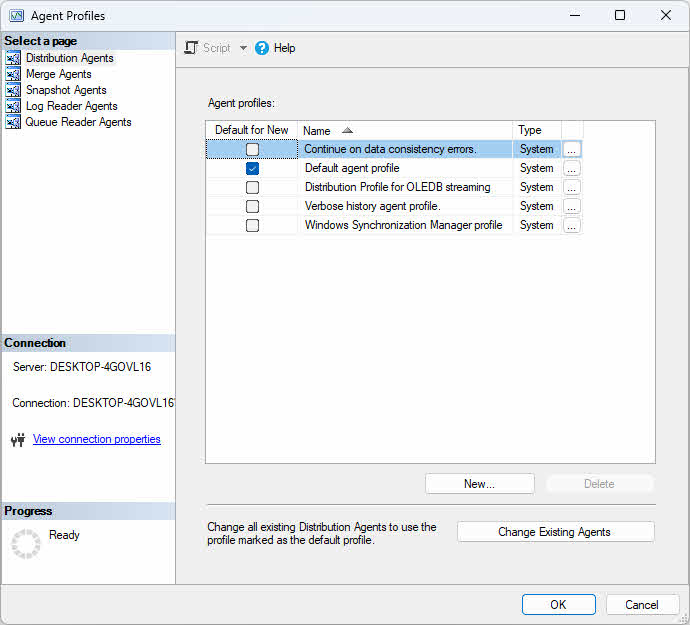
I profili degli agenti contengono set di parametri che controllano il comportamento degli agenti. SQL Server fornisce profili predefiniti ottimizzati per scenari comuni ed è possibile creare profili personalizzati per esigenze specifiche.
Per modificare i profili degli agenti:
- In Esplora oggetti, espandere replicazione.
- Fare clic con replicazione e seleziona Proprietà del distributore.
- Clicca su Impostazioni predefinite del profilo pulsante.
- Selezionare un tipo di agente (Snapshot, Lettore log, Distribuzione o Unione) dal menu a discesa.
- Seleziona un profilo e clicca Proprietà a Confronto per visualizzare i valori dei parametri.
- Clicchi Nuovo profilo per creare un profilo personalizzato basato su uno esistente.
- Modificare i parametri secondo necessità e fare clic OK.
Applica un profilo a un agente modificando le proprietà dell'abbonamento e selezionando il profilo desiderato dal menu a discesa Profilo agente.
5.3.3 Parametri e impostazioni dell'agente
I parametri dell'agente ottimizzano le prestazioni e il comportamento. I parametri chiave per l'agente di distribuzione includono CommitBatchSize (numero di transazioni applicate per commit), CommitBatchThreshold (numero di comandi prima del commit), SubscriptionStreams (connessioni parallele per una distribuzione più rapida) e QueryTimeout (timeout per i comandi).
Per Log Reader Agent, i parametri importanti includono ReadBatchSize (transazioni lette per scansione), ReadBatchThreshold (comandi prima della consegna) e PollingInterval (ritardo tra le scansioni del log). Regolare questi parametri in base al volume delle transazioni e ai requisiti di latenza.
5.4 Considerazioni su backup e ripristino
Il backup dei database coinvolti nella replica richiede considerazioni particolari. Per il database del publisher, sono essenziali backup completi e regolari del log delle transazioni. Contrassegnare il backup del database per il supporto della replica utilizzando l'opzione WITH REPLICATION quando si esegue il backup dei database nella replica transazionale. Eseguire regolarmente il backup del database di distribuzione per proteggere la configurazione della replica.
Quando si ripristina un database di pubblicazione sullo stesso server con lo stesso nome, utilizzare l'opzione WITH KEEP_REPLICATION per preservare lo stato di replica. Questa opzione garantisce che le transazioni non ancora elaborate dall'agente di lettura log rimangano contrassegnate per la replica, consentendo alla replica di continuare automaticamente senza reinizializzare le sottoscrizioni.
Negli scenari di disaster recovery in cui i backup non sono disponibili, sono corrotti o i file del database sono danneggiati, potrebbero essere necessari strumenti di ripristino specializzati. DataNumen SQL Recovery può estrarre dati da file MDF e NDF corrotti o inaccessibili, offrendo un'opzione di ultima istanza quando le procedure di ripristino standard falliscono.
Per ulteriori dettagli su SQL Server backup, vedere il nostro guida completa.
6. Domande frequenti (FAQ)
D: Qual è la differenza tra snapshot e replica transazionale?
A: La replica snapshot esegue una copia completa dei dati in un momento specifico e la applica all'abbonato, adatta per dati che cambiano raramente. La replica transazionaletarts con uno snapshot iniziale e poi replica continuamente le singole transazioni non appena si verificano, garantendo una sincronizzazione quasi in tempo reale per i dati che cambiano frequentemente.
D: Posso replicare tra diversi SQL Server versioni?
A: Sì, SQL Server La replica supporta la compatibilità di versione entro un intervallo limitato. La versione del distributore deve essere uguale o superiore alla versione del publisher e il subscriber può essere entro due versioni dal publisher. Ad esempio, se il publisher è SQL Server 2016, l'abbonato può essere SQL Server 2012, 2014, 2016, 2017 o 2019.
D: Come posso gestire i conflitti nella replica di tipo merge?
R: La replica tramite merge offre meccanismi integrati di rilevamento e risoluzione dei conflitti. È possibile configurare risolutori di conflitti a livello di articolo, scegliendo tra risolutori integrati o implementando risolutori di conflitti personalizzati. I conflitti vengono in genere risolti utilizzando metodi basati su priorità o timestamp, con la possibilità di registrarli per la revisione manuale.
D: Quali sono gli impatti della replica sulle prestazioni?
R: La replicazione influisce sulle prestazioni in diversi modi: il publisher subisce un sovraccarico dovuto al monitoraggio delle modifiche e alla generazione di snapshot, il distributor utilizza risorse per archiviare e inoltrare le transazioni e la larghezza di banda di rete viene consumata durante il trasferimento dei dati. L'impatto varia a seconda del tipo di replicazione: la replicazione snapshot causa picchi periodici ad alto impatto, mentre la replicazione transazionale mantiene un carico più coerente ma continuo.
D: Come posso proteggere la mia topologia di replicazione?
A: Proteggi la tua topologia di replica implementando diverse best practice: usa l'autenticazione di Windows o un'autenticazione avanzata SQL Server autenticazione, crittografare le connessioni tramite TLS, proteggere la cartella snapshot con appropriate NTFS autorizzazioni, configurare l'elenco di accesso alle pubblicazioni (PAL) per controllare l'accesso, utilizzare account di servizio separati con autorizzazioni minime richieste per ciascun agente di replicazione e controllare regolarmente le impostazioni di sicurezza della replicazione.
D: Posso replicare nel database SQL di Azure?
R: Sì, è possibile replicare nel database SQL di Azure utilizzando la replica transazionale con un'istanza locale SQL Server o Azure SQL Managed Instance come server di pubblicazione e distributore. Il database SQL di Azure può fungere da sottoscrittore, ma non da server di pubblicazione o distributore. La replica di tipo merge e la replica peer-to-peer non sono supportate con il database SQL di Azure.
D: Come posso monitorare il ritardo di replicazione?
A: Monitorare il ritardo di replicazione utilizzando Replication Monitor in SQL Server Management Studio, che visualizza le metriche di latenza per ogni sottoscrizione. È inoltre possibile interrogare le tabelle del database di distribuzione come MSdistribution_history e MSrepl_commands, utilizzare contatori delle prestazioni specifici per gli agenti di replica o impostare avvisi basati sulle soglie di latenza per rilevare e gestire in modo proattivo i ritardi di sincronizzazione.
D: Cosa succede quando un abbonato è offline?
R: Quando un abbonato è offline, il comportamento dipende dal tipo di replica. Per la replica transazionale, le transazioni si accumulano nel database di distribuzione finché l'abbonato non torna online, dopodiché la sincronizzazione riprende. Per la replica di tipo merge, le modifiche vengono tracciate su entrambi i lati e unite al ripristino della connettività. L'impostazione del periodo di conservazione determina per quanto tempo i dati vengono conservati prima di dover essere reinizializzati.
D: Come posso aggiungere nuovi articoli a una pubblicazione esistente?
A: Per aggiungere nuovi articoli a una pubblicazione esistente, utilizzare SQL Server Management Studio per modificare le proprietà della pubblicazione e selezionare oggetti aggiuntivi, oppure utilizzare la stored procedure sp_addarticle. Dopo aver aggiunto gli articoli, generare un nuovo snapshot e reinizializzare tutte le sottoscrizioni per garantire che le sottoscrizioni ricevano i nuovi articoli. Alcune modifiche potrebbero richiedere la reinizializzazione delle sottoscrizioni, a seconda delle impostazioni di pubblicazione.
D: Come posso rimuovere la replica da un database?
R: Per rimuovere la replica da un database, eliminare prima tutte le sottoscrizioni tramite sp_dropsubscription, quindi eliminare la pubblicazione tramite sp_droppublication e infine disabilitare la pubblicazione sul database tramite sp_replicationdboption. Se il server è un distributore, disabilitare la distribuzione tramite sp_dropdistributor. Eseguire sempre il backup dei database prima di rimuovere la configurazione della replica.
D: Qual è la differenza tra SQL Server Replicazione e gruppi di disponibilità AlwaysOn?
A: La replica è una soluzione di distribuzione e integrazione dei dati che opera a livello di oggetto, mentre Gruppi di disponibilità sempre attivi è una soluzione ad alta disponibilità e ripristino di emergenza che opera a livello di database.
7. CONCLUSIONE
SQL Server La replica fornisce un framework robusto per la distribuzione e la sincronizzazione dei dati su più database e posizioni. La tecnologia supporta vari scenari attraverso diverse tipologie di replica.
La scelta della strategia di replicazione più adatta dipende dalle esigenze specifiche. È necessario considerare la frequenza di modifica dei dati, i requisiti di latenza, la necessità di aggiornamenti da parte degli abbonati, le caratteristiche della rete e le esigenze di autonomia degli abbonati. La replica snapshot è ideale per dati di riferimento che cambiano raramente, dove la latenza non è critica. La replica transazionale è adatta a scenari ad alto volume che richiedono bassa latenza e un flusso di dati principalmente unidirezionale.
Scegliete la replicazione tramite merge quando gli abbonati necessitano di un funzionamento autonomo con funzionalità offline e sincronizzazione bidirezionale. Implementate la replicazione peer-to-peer per bilanciare il carico delle operazioni di lettura su più nodi attivi con coerenza quasi in tempo reale. Valutate approcci ibridi che combinano più tipi di replicazione per scenari complessi con requisiti diversi.
Referenze
- Documento ufficiale Microsoft: SQL Server replicazione
- Documento ufficiale Microsoft: Tipi di replica
- Documento ufficiale Microsoft: Peer-to-Peer – Replica transazionale
L'autore
Yuan Sheng è un amministratore di database senior (DBA) con oltre 10 anni di esperienza in SQL Server ambienti e gestione di database aziendali. Ha risolto con successo centinaia di scenari di ripristino di database in aziende di servizi finanziari, sanitari e manifatturiere.
Yuan è specializzato in SQL Server Ripristino di database, soluzioni ad alta disponibilità e ottimizzazione delle prestazioni. La sua vasta esperienza pratica include la gestione di database multi-terabyte, l'implementazione di gruppi di disponibilità Always On e lo sviluppo di strategie di backup e ripristino automatizzate per sistemi aziendali mission-critical.
Grazie alla sua competenza tecnica e al suo approccio pratico, Yuan si concentra sulla creazione di guide complete che aiutano gli amministratori di database e i professionisti IT a risolvere problemi complessi SQL Server sfide in modo efficiente. Si mantiene aggiornato con le ultime SQL Server versioni e le tecnologie di database in continua evoluzione di Microsoft, testando regolarmente gli scenari di ripristino per garantire che le sue raccomandazioni riflettano le migliori pratiche del mondo reale.
Hai domande su SQL Server recupero o hai bisogno di ulteriore assistenza per la risoluzione dei problemi del database? Yuan accoglie feedback e suggerimenti per migliorare queste risorse tecniche.