1. 簡介 SQL Server 性能監視器
1.1 什麼是 SQL Server 效能監視器?
SQL Server 效能監視器是追蹤、分析和管理您的 SQL Server 資料庫.它涉及收集和解釋有關資料庫系統各個方面的數據,以確保最佳效能、預防問題並維護資料庫健康。

效能監控涵蓋追蹤查詢執行時間、資源利用率、索引效能、阻塞和死鎖以及資料庫成長模式。這種持續的監督有助於管理員在潛在問題影響使用者或業務運作之前發現它們。
1.2 效能監控的主要優勢
有效 SQL Server 效能監視器具有幾個關鍵優勢:
- 主動問題檢測: 在潛在問題影響用戶或業務運營之前識別並解決這些問題
- 性能優化: 找出瓶頸和低效率,以提高整體資料庫效能
- 容量規劃: 根據歷史數據預測資源需求並規劃未來成長
- 合規性和安全性: 確保遵守監管要求並檢測可疑活動
1.3 常見的性能挑戰
如果沒有適當的 SQL 資料庫效能監視器,組織將面臨多種風險:
- 意外停機擾亂業務運營
- 應用程式效能不佳影響使用者體驗
- 資料遺失或損壞
- 資源利用效率低下導致不必要的osts
- 沮喪的用戶和潛在的收入損失
根據 2023 年 IDC 的一項研究,65% 的資料庫效能問題源自於糟糕的監控或優化實踐。
2. 了解 Windows 效能監視器 (PerfMon)
2.1 什麼是 Windows 效能監視器?
Windows 效能監視器 (PerfMon) 是一款內建的 Windows 工具,用於監控系統資源和應用程式效能。 SQL Server 管理員,PerfMon 提供了有關作業系統和 SQL Server 指標,這對於全面的性能分析至關重要。
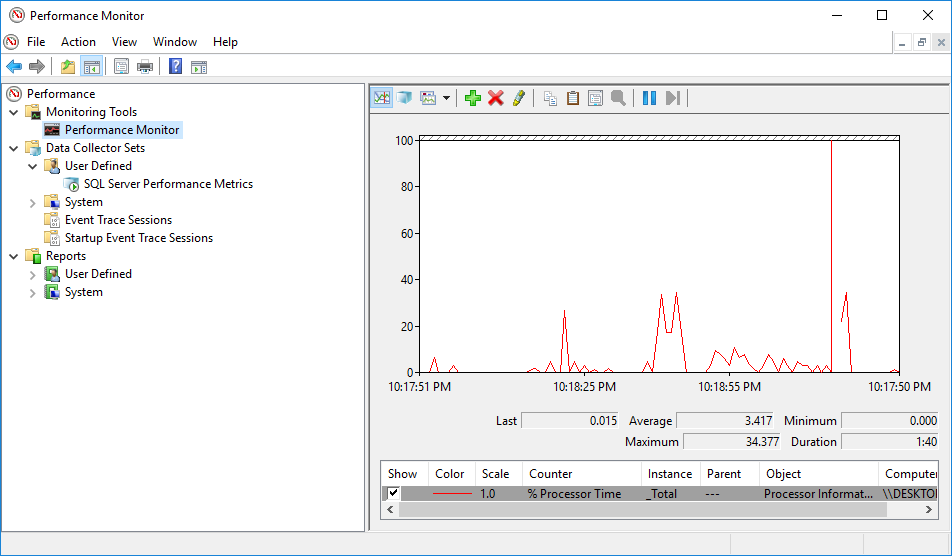
PerfMon 會定期測量效能統計數據,並將這些統計資料儲存到檔案中以供日後分析。資料庫管理員可以選擇時間間隔、文件格式以及要監控的統計資料。該工具不 SQL Server-特定—系統管理員使用它來監控 Windows 本身、Exchange、檔案伺服器以及任何可能遇到瓶頸的應用程式。
2.2 啟動效能監視器
您可以使用多種方法啟動效能監視器:
- 點擊 Start,輸入 性能監視器 在搜尋框中,點選搜尋結果中的「Performand Monitor」:

- 媒體中心 的Windows + R,輸入 性能監視器,然後按 進入

- 前往 控制面板 -> 系統和安全 -> 管理工具 -> 性能監視器

3。 必要 SQL Server 性能計數器
3.1 記憶體效能計數器
記憶體計數器對於監控至關重要 SQL Server 效能,因為它們表明您的資料庫是否具有足夠的記憶體資源。
可用兆位元組
此計數器顯示可立即分配的實體記憶體量。它應該保持相對穩定,理想情況下不會低於 4096 MB。較低的值可能表明 SQL Server的最大記憶體設定保留為預設值,或非SQL Server 應用程式正在消耗記憶體。
頁面預期壽命
頁面預期壽命衡量頁面在緩衝池中未被引用的停留時間(以秒為單位)。正常值為 300 秒或以上。較低的值表示記憶體壓力較大且緩衝區週轉率過高,從而降低了快取效率。
緩衝區快取命中率
此計數器指示使用 SQL 緩衝區快取(記憶體)而非從磁碟讀取資料來應答的資料請求的百分比。該值通常達到或超過 99%。較低的值表明 SQL Server 需要更多記憶體或仍在恢復後tart.
內存授予待定
這顯示了等待記憶體的進程數 SQL Server。在正常情況下,該值應始終為 0。數值越高,表示記憶體分配越不足, SQL Server.
Tar取得伺服器記憶體與總伺服器記憶體
Tar取得伺服器記憶體指示理想的記憶體量 SQL Server 想要使用。伺服器總記憶體顯示 SQL Server 目前使用。這些值之間的比率應約為 1。顯著差異可能表示記憶體壓力或可用記憶體不足。
3.2 處理器效能計數器
CPU 計數器有助於識別處理器瓶頸並了解 SQL Server 利用運算資源。
處理器時間百分比
這衡量的是處理器執行非空閒執行緒所花費時間的百分比。在活躍伺服器上,該值可能會飆升至 100%,但持續超過 70-75% 的使用率通常表示用戶有效能問題。索引缺失或不足通常會導致 CPU 使用率過高。
特權時間百分比
處理器時間分為使用者模式和特權(核心)模式處理。所有磁碟存取和 I/O 均在核心模式下進行。如果此計數器超過 25%,則系統可能執行了過多的 I/O。正常值在 5% 到 10% 之間。
處理器佇列長度
此計數器顯示正在等待 CPU 資源的執行緒。值持續高於 1(除 SQL Server 備份壓縮)指示 CPU 壓力。這通常意味著其他應用程式安裝在 SQL Server 機器,這違反了最佳實踐。
上下文切換次數/秒
這衡量處理器在執行緒之間切換的頻率。過多的上下文切換會影響效能,並表示系統負載過高。
3.3 磁碟 I/O 效能計數器
磁碟計數器對於 SQL 效能監控至關重要,因為磁碟 I/O 通常成為資料庫系統的主要瓶頸。
磁碟時間百分比
這記錄了磁碟用於讀取/寫入操作的時間百分比。如果數值持續高於 85%,則表示存在 I/O 瓶頸。由於磁碟比記憶體慢得多,因此降低此指標可以提高效能。
平均磁碟秒/讀取和平均磁碟秒/寫入
這些計數器測量讀寫操作的平均時間(以秒為單位)。如果平均值超過 10-20 毫秒,則表示磁碟處理資料的時間過長。交易日誌驅動器尤其需要快速的寫入效能。
磁碟佇列長度
這顯示了對磁碟的未完成讀寫請求。如果值持續高於 2(對於 RAID 陣列,每個磁碟為 2),則表示磁碟無法滿足 I/O 請求。
磁碟位元組數/秒
此項用於監控磁碟的資料傳輸速率。如果超出磁碟的額定容量,資料就會開始積壓,磁碟佇列長度會增加。
磁碟傳輸量/秒
這會追蹤在磁碟上執行的讀取/寫入操作的次數。 SQL Server 資料存取通常是隨機的,由於驅動器磁頭移動,存取速度會比較慢。請確保此值低於磁碟機的最大額定值(標準磁碟機通常為 100/秒)。
3.4 SQL Server 特定計數器
3.4.1 緩衝區管理器計數器
緩衝區管理器計數器監視器 SQL Server的記憶體緩衝區操作:
- 頁面讀取次數/秒: 實體資料庫頁面讀取的累計次數
- 頁面寫入/秒: 實體資料庫頁面寫入的累計次數
- 惰性寫入/秒: 惰性寫入器為釋放記憶體而寫入的緩衝區數量
- 檢查點頁數/秒: 檢查點或其他需要刷新所有髒頁的操作刷新的頁面
3.4.2 SQL統計計數器
這些計數器可以洞察 SQL Server 查詢處理:
- 每秒批次請求數: 伺服器收到的 SQL 批次請求數。這可作為伺服器活動的基準。
- SQL 編譯/秒: SQL 編譯次數。應為每秒總批量請求數的 10% 或更少
- SQL 重新編譯/秒: SQL 重新編譯的次數。也應為每秒總批量請求數的 10% 或更少
3.4.3 通用統計計數器
- 用戶連線: 連接到系統的使用者數量。用作追蹤連線隨時間增長的基準
- 進程被阻止: 目前阻塞進程數。理想情況下應為 0
3.4.4 記憶體管理器計數器
- 內存授權待定: 等待工作區記憶體授予的進程總數。理想情況下應為 0
4. 設定效能監視器 SQL Server(Windows Vista/Server 2008 及更高版本)
首先,我們需要建立一個容器來更輕鬆地管理計數器:
- 對於 Windows Vista / Server 2008 及更高版本,您可以在此部分建立資料收集器集。
- 對於 Windows XP / Server 2003 及更早版本,您可以在 下一節.
4.1 什麼是資料收集器集?
資料收集器集將效能計數器、事件追蹤資料和系統配置資訊組織到單一收集單元。它們比簡單的計數器日誌更靈活,並支援自動、定期的資料收集,從而實現全面的 SQL 資料庫效能監控。
4.2 建立資料收集器集
建立自訂資料收集器集來監控 SQL Server 性能計數器:
- 開啟效能監視器
- 拓展 資料收集器集
- 右鍵單擊 用戶自定義
- 選擇 New -> 資料收集器集

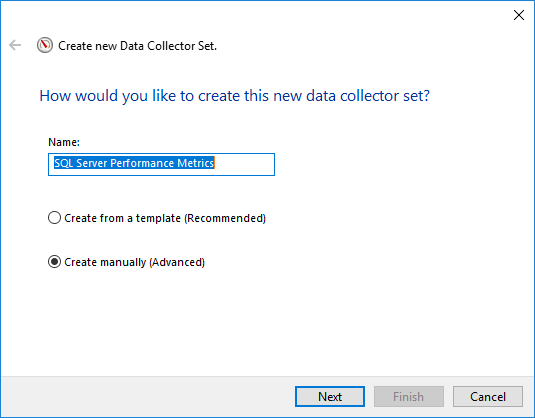
- 輸入描述性名稱(例如,“SQL Server 績效指標”
- 選擇 手動建立(進階)

- 點擊 下一則
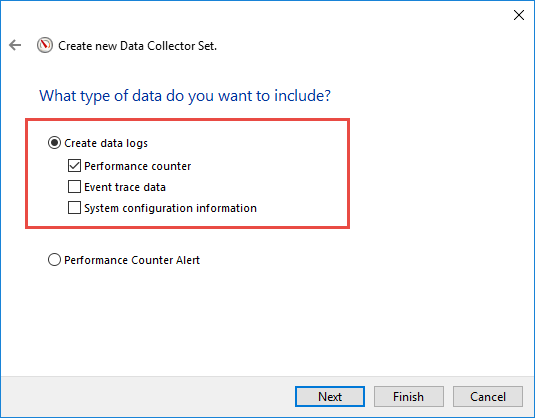
- 勾選 建立資料日誌->效能計數器
- 點擊 下一則
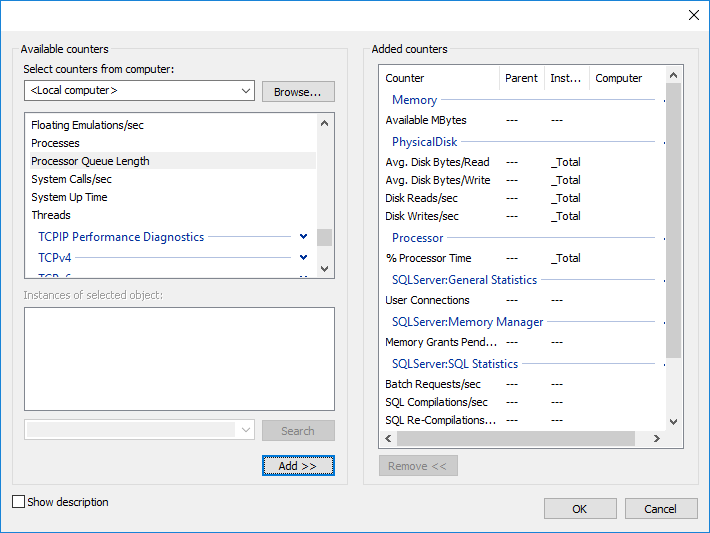
- 點擊 新增 選擇櫃檯
- 新增 所需 SQL Server 和系統計數器.

- 套裝 採樣間隔
- 對於常規監測,使用 1 分鐘(60 秒)
- 對於主動故障排除,使用 15-30 秒
- 避免長期運行高頻捕獲,因為它們會影響性能並產生過多數據。
- 點擊 下一則
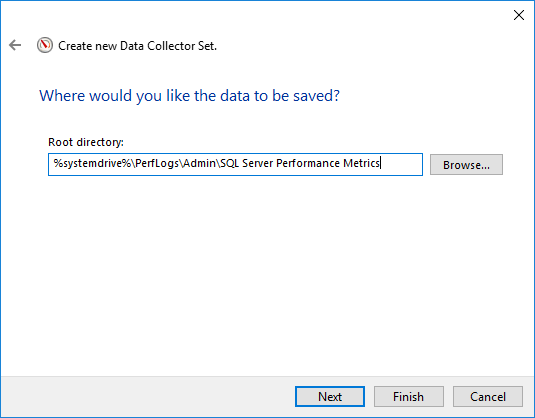
- 選擇保存日誌的位置
- 點擊 完,將建立一個新的資料收集器集。
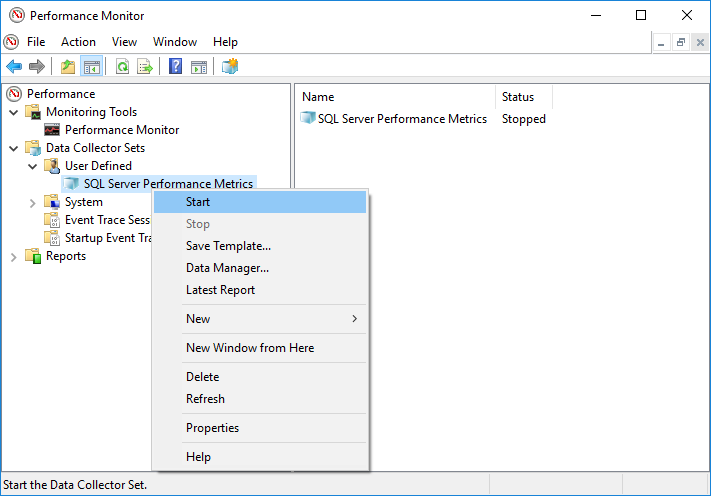
- 預設情況下,新的資料收集器集將 不 是tar自動。您需要在左側面板中找到它,在 性能 -> 資料收集器集 -> 用戶自定義 -> 您的資料收集器,右鍵單擊它並選擇 Start

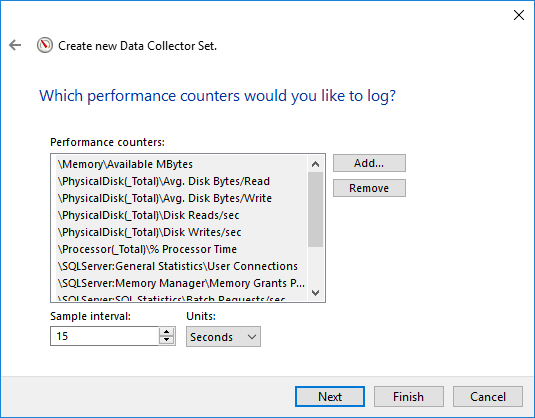
4.3 要新增的關鍵計數器
- 記憶體 -> 可用兆位元組
- 實體磁碟 -> 平均磁碟秒/讀取(除 _Total 之外的所有實例)
- 實體磁碟 -> 平均磁碟秒/寫入(除 _Total 之外的所有實例)
- 實體磁碟 -> 磁碟讀取次數/秒(除 _Total 之外的所有實例)
- 實體磁碟 -> 磁碟寫入次數/秒(除 _Total 之外的所有實例)
- 處理器 -> % 處理器時間(除 _Total 之外的所有實例)
- SQLServer:常規統計資訊->使用者連接
- SQLServer:記憶體管理器->記憶體授予待定
- SQLServer:SQL 統計資料 -> 批次請求/秒
- SQLServer:SQL 統計資料 -> SQL 編譯次數/秒
- SQLServer:SQL 統計資料 -> SQL 重新編譯次數/秒
- 系統 -> 處理器佇列長度
4.4 設定停止條件
配置停止條件以防止資料無限增長:
- 建立資料收集器集後,右鍵單擊它並選擇 產品特性
- 在操作欄點擊 停止條件 選項卡
- 啟用 總時長
- 將持續時間設定為 1 天(24 小時)
- 點擊 OK 救
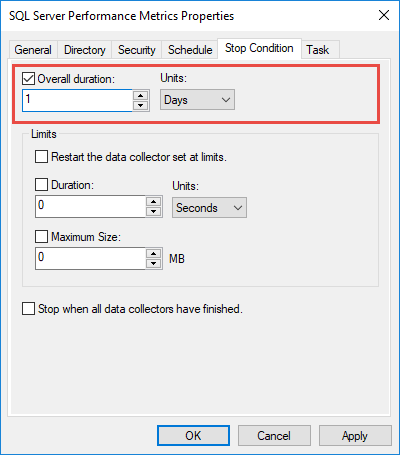
這可確保日誌不會變得太大,並自動重新tar如果已安排。
4.5 安排資料收集
自動收集數據以確保一致的監控:
- 右鍵單擊資料收集器集並選擇 產品特性
- 在操作欄點擊 活動行程 選項卡
- 點擊 新增 建立新的時間表
- 配置tart 日期和時間
- 設定重複模式(例如,每天)
- 點擊 OK 保存時間表
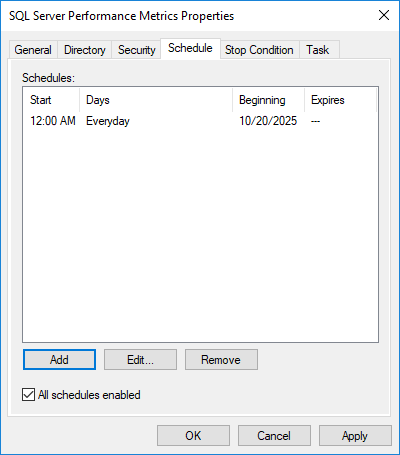
對於自動tartup,將資料收集器集配置為tart 在伺服器啟動時透過建立tarWindows 工作排程器中的 tup 觸發器。
5. 設定效能監視器 SQL Server(Windows XP/Server 2003 及更早版本)
對於 Windows XP / Server 2003 及更早版本,您可以建立計數器日誌,這樣您就可以選擇一組效能計數器並定期將它們記錄到檔案中。
5.1 建立計數器日誌
請依照以下步驟建立新的計數器日誌:
- 開啟效能監視器
- 拓展 性能日誌和警報 在左側窗格中
- 右鍵單擊 計數器日誌
- 選擇 新日誌設定
- 使用資料庫伺服器名稱命名日誌(例如“ProductionSQL01”)
- 點擊 OK 開始配置
為每個伺服器建立單獨的計數器日誌可讓您測試單一伺服器的效能,而無需同時收集所有伺服器的資料。
5.2 添加性能計數器
建立計數器日誌後,新增要監視的特定效能計數器:
- 在操作欄點擊 新增計數器 按鍵
- 更改電腦名稱以指向您的 SQL Server 例
- 媒體中心 標籤 載入可用的效能對象
- 從下拉式選單中選擇一個效能物件(例如, 記憶體應用)
- 從中選擇特定的計數器 列表
- 如果適用,請選擇實例cable(例如,單一處理器或磁碟)
- 點擊 新增 包括計數器
- 對所有需要的計數器重複此操作
- 點擊 關閉 完成時
5.3 配置採樣間隔
採樣間隔決定了效能監視器收集資料的頻率。請根據監控需求配置適當的間隔:
- 在計數器日誌屬性中,找到 採樣數據間隔
- 設定間隔(預設為15秒)
- 對於基線監測,每日收集間隔為 1 分鐘
- 為了進行故障排除,請使用 15-30 秒的間隔進行短時間爆發
- 點擊 OK 申請
請記住,較小的間隔會產生更多數據,這會增加渲染和分析的難度。較大的間隔可能會錯過重要的峰值。務必平衡資料粒度與儲存和分析需求。
5.4 設定日誌文件
正確的日誌檔案配置可確保資料高效且可存取地儲存:
- 在操作欄點擊 日誌文件 計數器日誌屬性中的選項卡
- 將日誌檔案類型變更為 文字檔案(逗號分隔) 輕鬆導入 Excel
- 點擊 配置
- 將檔案路徑設定為專用位置(例如,共用的 PerformanceLogs 資料夾)
- 點擊 OK 確認
使用可透過網路存取的共用來儲存日誌,以便您可以遠端存取檔案並與其他使用者共用。
5.5 設定憑證
配置適當的憑證,以便效能監視器可以存取遠端 SQL Server 實例:
- 在計數器日誌屬性中,找到 運作方式
- 按以下格式輸入您的網域使用者名稱: 網域\使用者名稱
- 點擊 設置密碼
- 輸入並確認您的密碼
- 點擊 OK 救
這允許 PerfMon 服務使用您的網域權限而不是自己的憑證來收集統計資料。
6.分析效能監視器數據
6.1 在效能監視器中查看日誌文件
效能監視器可以顯示已儲存的日誌檔案的歷史資料:
- 開啟效能監視器
- 在左側窗格中,單擊 監控工具 -> 性能監視器.
- 右鍵單擊圖形區域的任意位置
- 選擇 產品特性

- 在操作欄點擊 來源 選項卡
- 選擇 紀錄檔案 單選按鈕
- 點擊 新增
- 導航到您的日誌檔案(.blg 或 .csv)
- 選擇文件,然後單擊 未結案工單

- 購買 時間範圍 滑桿選擇要分析的時間段
- 點擊 OK 關閉“屬性”對話框
- 點擊綠色加號圖示從日誌檔案新增計數器
- 選擇要顯示的計數器
- 點擊 OK
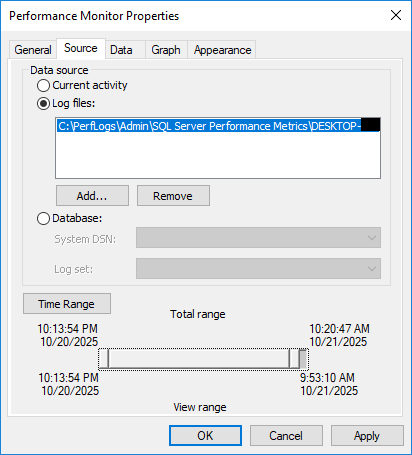
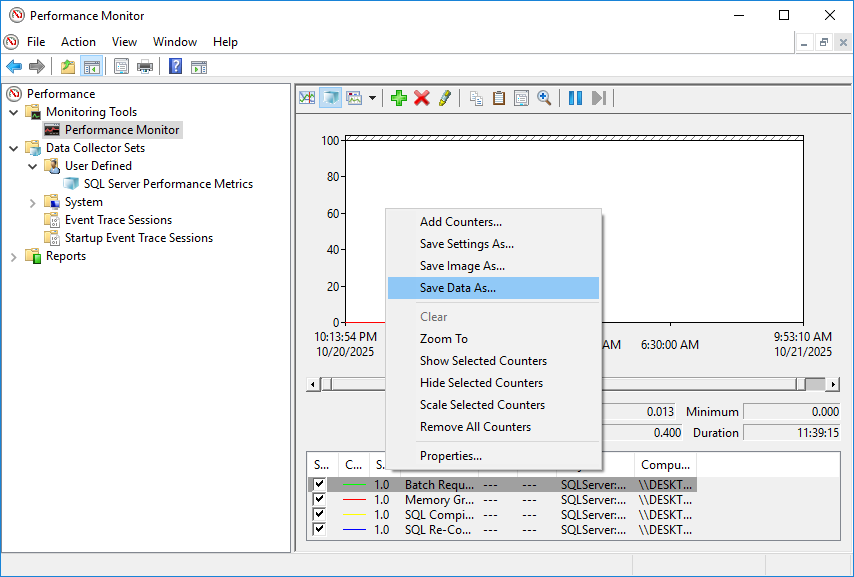
圖表現在將顯示日誌檔案中的歷史資料。使用“屬性”中的“時間範圍”滑桿可以縮小特定時間段以進行詳細分析。
6.2 將資料匯出到 Excel
Excel 為效能計數器資料提供了強大的分析功能:
- 打開效能監視器並載入日誌文件
- 右鍵單擊圖形區域的任意位置
- 選擇 數據另存為
- 選擇文件的位置
- 選擇 文字檔案(逗號分隔)(.csv) 從下拉式選單中
- 點擊 節省
- 在 Excel 中開啟 CSV 文件
格式化導出的資料以便更好地進行分析:
- 刪除半空的第 2 行並清除儲存格 A1
- 將 A 列格式化為日期/時間
- 使用零小數和千位分隔符號格式化數字列
- 尋找並取代標題中的伺服器名稱(例如,將“\\SERVERNAME”替換為空白)
- 清理標題中的物件名稱(例如「記憶體」、「實體磁碟」、「處理器」)
- 將標題字體大小減小至 8 點,以提高可見度
6.3 解釋計數器值
6.3.1 記憶體計數器分析
分析記憶體計數器時,請尋找以下指標:
- 可用兆位元組: 應始終保持在 4096 MB 以上
- 頁面預期壽命: 300 秒以上的值表示記憶體健康。較低的值表示記憶體壓力
- 緩衝區快取命中率: 應達到或超過 99%。較低的值表示磁碟讀取過多
- 內存授權待定: 應始終為 0。任何正值均表示內存tar假期
6.3.2 CPU計數器分析
CPU效能指標包括:
- 處理器時間百分比: 持續使用率超過 75% 表示有效能問題。峰值達到 100% 是正常現象,但不應持續存在
- 處理器佇列長度: 大於 1 的值表示 CPU 壓力較大。檢查任務管理器以確定哪些進程佔用了 CPU
- 特權時間百分比: 應保持在 5-10% 之間。高於 25% 的值表示 I/O 操作過多
6.3.3 磁碟計數器分析
磁碟效能閾值:
- 平均磁碟秒數/讀取和寫入: 應保持在 10-20 毫秒以下。值越高,表示磁碟子系統越慢
- 磁碟佇列長度: 值持續高於 2(或 RAID 中每個磁碟 2)表示存在 I/O 瓶頸
- 磁碟時間百分比: 持續高於 85% 的值表示磁碟飽和
6.4 使用公式和統計數據
向 Excel 新增統計公式以便快速分析:
- 在電子表格頂部插入 7 個空白行
- 在 A 欄中加入標籤:平均值、中位數、最小值、最大值、標準差
- 在儲存格 B2 中,輸入:=AVERAGE(B9:B100)(將 B100 調整為最後一個資料行)
- 在儲存格 B3 中輸入:=MEDIAN(B9:B100)
- 在儲存格 B4 中輸入:=MIN(B9:B100)
- 在儲存格 B5 中輸入:=MAX(B9:B100)
- 在儲存格 B6 中輸入:=STDEV(B9:B100)
- 在所有計數器列中複製公式
- 選擇儲存格 B9 並按 Alt+W+F+Enter 凍結窗格
這些統計數據有助於識別每個計數器的趨勢、異常值和正常操作範圍。
7. 日誌效能分析(PAL)工具
7.1 PAL 簡介
日誌效能分析 (PAL) 是一款由 Clint Huffman 開發的免費工具,用於分析效能監視器日誌並產生包含閾值分析的 HTML 報告。 PAL 會將您的效能數據與已知閾值進行比較,並提供詳細的建議,以幫助您 SQL Server 性能優化。
從 GitHub 儲存庫下載 PAL: https://github.com/clinthuffman/PAL ![]()
7.2 設定 PAL
請依照以下步驟安裝 PAL:
- 從 GitHub 下載 PAL 安裝文件
- 運行安裝程序
- 點擊 下一則 在歡迎畫面上
- 查看並接受安裝目錄
- 點擊 下一則 繼續
- 點擊 安裝 開始安裝
- 等待安裝完成
- 點擊 完
7.3 使用 PAL 處理日誌文件
使用 PAL 分析效能監視器日誌:
- 從 S 啟動 PALtart 選單或安裝目錄
- 在操作欄點擊 計數器日誌 選項卡
- 點擊 瀏覽 選擇你的 .blg 文件
- 導航到您的效能監視器日誌文件
- 點擊 未結案工單
- 在操作欄點擊 閾值文件 選項卡
- 從下拉式選單中選擇一個閾值檔案(例如,“SQL Server 2016”)
- 在操作欄點擊 解答疑問(Questions): 選項卡
- 回答有關係統配置的問題
- 請指定您的 SQL Server 是 OLTP 還是資料倉儲
- 輸入可用的總 RAM
- 在操作欄點擊 輸出選項 選項卡
- 選擇 HTML 報告的輸出目錄
- 勾選 HTML 輸出格式
- 在操作欄點擊 執行 選項卡
- 檢查您的選擇
- 勾選 Star現在執行
- 點擊 完
7.4 分析 PAL 報告
PAL 完成分析後,會產生一份 HTML 報告,其中包含:
- 績效問題執行摘要
- 帶有圖表的詳細計數器分析
- 閾值違規以顏色突出顯示
- 針對每個問題的具體建議
- 歷史趨勢和模式
該報告使用顏色編碼來指示嚴重程度:紅色表示嚴重問題,黃色表示警告,綠色表示指標正常。查看每個部分以了解效能瓶頸,並遵循 PAL 的最佳化建議。
8.替代 SQL Server 監控工具
8.1 內建 SQL Server 工具
8.1.1 SQL Server 活動監視器
SQL Server 活動監視器 顯示關於以下方面的即時信息 SQL Server 流程和效能:
- 未結案工單 SQL Server Management Studio(SSMS)並連接到您的伺服器實例
- 在物件資源管理器中右鍵點選伺服器名稱
- 選擇 活動監視器

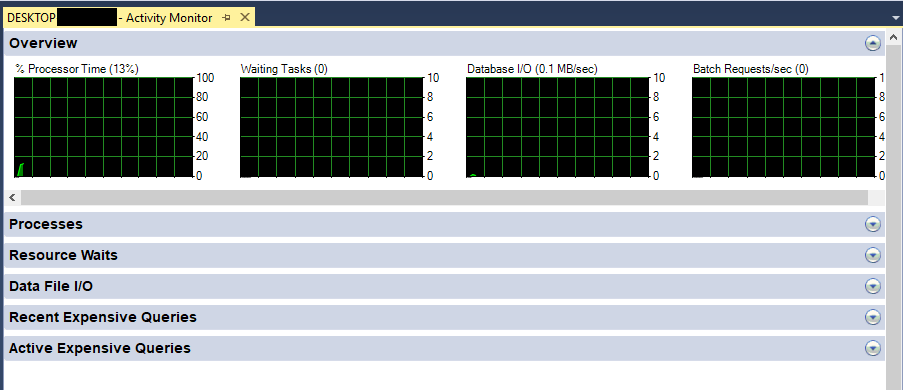
活動監視器顯示進程、資源等待、資料檔案 I/O 以及近期開銷較大的查詢。它提供對當前資料庫活動的快速洞察,但不儲存歷史資料。
8.1.2 SQL Server 性能儀表板
SQL Server Management Studio 包含內建效能報表:
- In SQL Server Management Studio(SSMS),右鍵點選 SQL Server 物件資源管理器中的實例
- 選擇 分析報告 -> 標準報表
- 從可用的報告中選擇,例如 性能儀表板

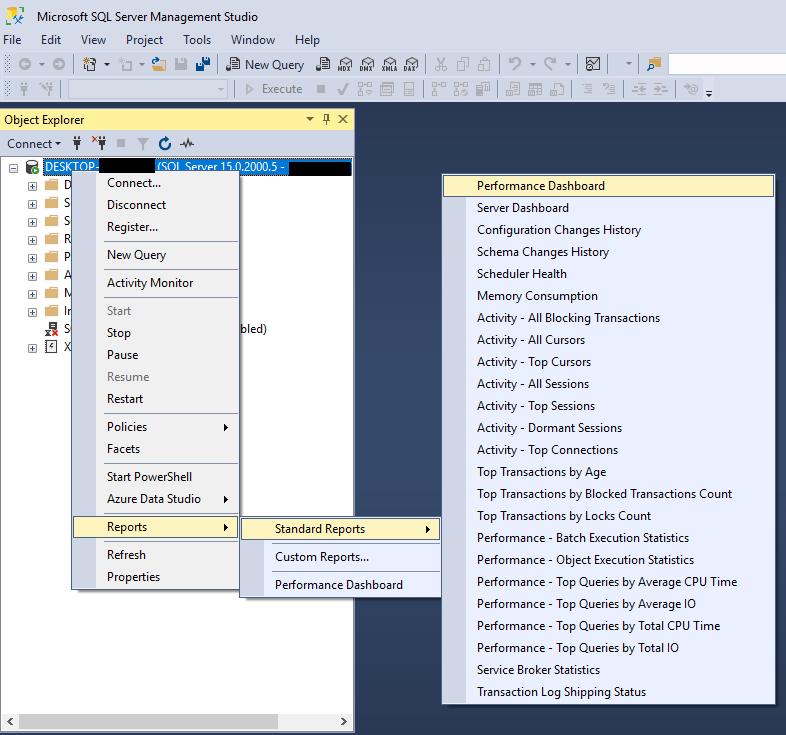
性能儀錶板提供了以下方面的視覺洞察 SQL Server 執行個體效能,包括系統 CPU 使用率、目前等待的請求以及效能指標。您可以透過「標準報告」選單存取它。
8.1.3 SQL Server 輪廓
SQL Server 輪廓 捕獲並分析 SQL Server 查詢執行、事務操作和登入活動等事件。
到tart SQL Server 分析器:
- In SQL Server Management Studio 中,按一下 工具 -> SQL Server 輪廓

Profiler 會產生顯著的效能開銷,因此請謹慎使用,最好在非尖峰時段使用。對於 most 場景下,擴展事件提供更好的效能且影響更小。
8.1.4 擴展事件
擴展活動 是一個內建的輕量級效能監控系統 SQL Server. 它取代 SQL Server 具有更好性能和更低開銷的分析器。
主要功能包括:
- 對特定事件進行細粒度監控
- 最小化性能影響
- 可自訂的活動會話
- 與 SSMS 和其他工具集成
- 支援複雜的過濾和聚合
透過 SSMS 建立擴展事件會話:
- In 對象資源管理器,展開你的伺服器並轉到 管理 -> 擴展事件 -> 會話
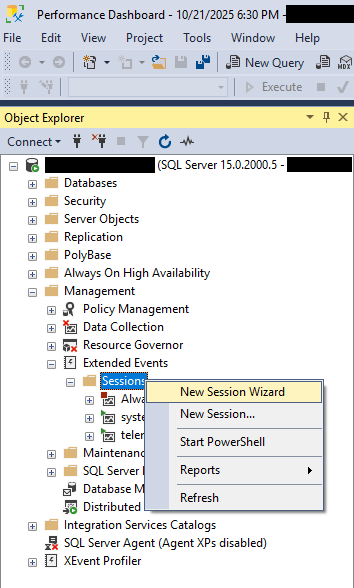
- 用鼠標右鍵單擊 會議 並選擇 新建會話精靈

- 按照說明tar開始新會話。
8.1.5 動態管理視圖(DMV)
DMV 公開了詳細的伺服器狀態信息,用於監控伺服器運行狀況、診斷問題和調整效能。主要的 DMV 包括:
- sys.dm_exec_query_stats: 查詢效能統計
- sys.dm_os_wait_stats: 影響伺服器效能的等待類型
- sys.dm_os_performance_counters: SQL Server 性能計數器數據
- sys.dm_exec_requests: 目前正在執行請求
- sys.dm_exec_sessions: 活躍用戶會話
使用 T-SQL 查詢這些視圖以存取即時效能資料和歷史指標。
基本用法
-- See all active connections
SELECT * FROM sys.dm_exec_connections;
-- View current sessions
SELECT * FROM sys.dm_exec_sessions;
-- Check database file stats
SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL);8.2 第三方監控解決方案
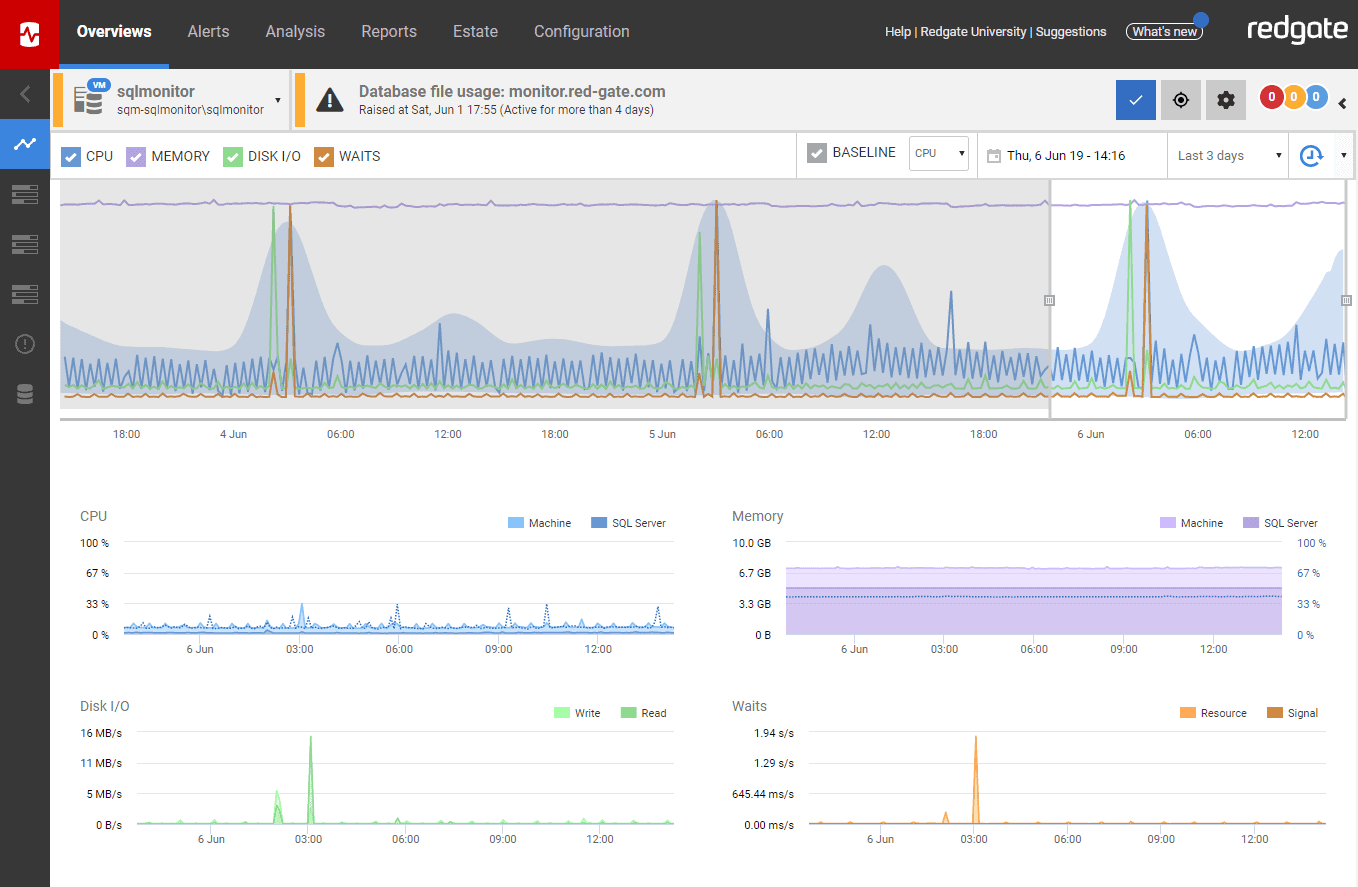
龍門SQL監視器
Redgate SQL Monitor 專注於監控 SQL Server 和 Azure SQL 資料庫環境。它提供全屋監控、可自訂的警報和儀表板、詳細的報告功能以及與其他 Redgate 工具的整合。
太陽風 SQL Server 監控工具
太陽風 SQL Server 監控工具,也稱為 SQL Sentry,旨在診斷、解決和預防嚴重的效能問題 SQL Server.
伊德拉的 SQL Server 效能監控工具
IDERA SQL 診斷ostic管理器功能強大 SQL Server 效能監控工具旨在協助主動效能監控、診斷ostics 和調整。
應用程式管理員的 SQL 監控
應用程式管理員提供了 Microsoft SQL Server 提供有用 IT 解決方案的監控工具。它旨在監督 SQL 資料庫的效能,同時識別錯誤並解決可能導致組織運作停止的問題。
8.3 開源監控工具
DBA 衝刺
DBA Dash 是一款免費的開源監控工具,可以洞察 SQL Server 健康狀況、性能和活動。它特別適用於中小型環境,包括每日 DBA 檢查、效能監控和設定追蹤。
SQL監視
SQLWATCH 提供去中心化、近乎即時的 SQL Server 以 5 秒為粒度的監控,用於捕捉工作負載峰值。它支援使用 Grafana 進行即時儀表板,並使用 Power BI 進行深入分析。該工具提供豐富的配置選項、零維護要求和無限的可擴充性。
操作伺服器
Opserver 由 Stack Exchange 開發,可監控多個系統,包括 SQL Server、Redis 和 Elasticsearch。它提供了整個基礎架構中 CPU、記憶體、網路和硬體統計資料的「所有伺服器」視圖。
sp_WhoIsActive
sp_WhoIsActive 是一個全面的活動監控預存程序,由 Adam Machanic 創建。它適用於所有 SQL Server 從 2005 年到目前版本,被廣泛使用 SQL Server 用於即時活動監控的 DBA。
若要使用 sp_WhoIsActive,請從 http://whoisactive.com/ 下載,將其安裝在資料庫中,然後執行:
EXEC sp_WhoIsActive
此過程顯示目前正在執行的查詢、等待資訊、阻塞詳細資訊和資源消耗。
9. 最佳實踐 SQL Server 性能監視器
9.1 建立性能基線
性能基準為您的 SQL Server 環境。沒有基線,您就無法確定目前指標是否表示有問題或代表典型行為。
透過以下方式建立基線:
- 收集正常運作期間至少一週的效能數據
- 在高峰時段和非高峰時段捕捉指標
- 記錄關鍵計數器的典型值
- 如果適用,記錄季節變化cable
- 儲存基準數據以便與未來指標進行比較
每季或在重大基礎架構變更、應用程式更新或資料庫修改後更新基準。
9.2 設定適當的警報閾值
配置智慧閾值以接收有意義的警報,而不會讓自己被通知淹沒:
- Memory Grants Pending > 0 表示記憶體壓力
- 處理器佇列長度 > 每個核心 2 表示存在 CPU 瓶頸
- 磁碟秒/讀取或寫入> 20ms 表示 I/O 速度慢
- 阻塞進程 > 5 表示爭用問題
- 頁面壽命預期 < 300 秒錶示記憶體壓力
根據基線資料和特定工作負載特徵調整閾值。使用能夠反映環境中正常變化的自適應閾值。
9.3 定期資料審查與分析
安排定期績效評估以確定趨勢和新出現的問題:
- 每日:查看高級指標和最新警報
- 每週:深入分析績效趨勢
- 每月:產生綜合報告並與基線進行比較
- 季度:審查產能規劃和長期趨勢
記錄調查結果並追蹤一段時間內的性能改進。
9.4 平衡監控開銷
監控本身會消耗資源,因此需要在資料收集和效能影響之間取得平衡:
- 使用 30-60 秒間隔進行連續監測
- 僅使用 15 秒間隔進行主動故障排除
- 限制資料收集器設定持續時間以避免資料過多
- 將日誌儲存在與資料庫檔案不同的磁碟機上
- 歸檔舊的效能資料以保持可管理的檔案大小
如果配置正確,效能監視器會增加最小的開銷,通常低於系統資源的 2%。
9.5 長期資料保留
保留效能資料以進行有意義的趨勢分析和容量規劃:
- 保留至少1-2年的性能數據
- 3-6 個月後將資料歸檔到單獨的儲存中
- 壓縮舊日誌檔案以節省空間
- 記錄影響性能的任何重大事件或變化
鑑於性能計數器數據相對較小,無限期地保留它通常是可行的,並且對於長期分析很有價值。
9.6 與 DevOps 實踐集成
將資料庫效能監控納入 CI/CD 管道:
- 在部署驗證中包含資料庫效能指標
- 自動執行新版本的效能測試
- 驗證程式碼變更不會對效能產生負面影響
- 為每個版本建立效能基準
- 將監控警報與事件管理系統集成
10. 常見效能問題故障排除
10.1 識別 CPU 瓶頸
CPU 瓶頸表現為查詢回應時間慢和處理器使用率高。請使用以下步驟診斷 CPU 問題:
- 檢查“處理器佇列長度”計數器。如果每個核心的值超過 2,則表示 CPU 壓力較大
- 檢查處理器時間百分比。持續超過 75% 的值表示存在 CPU 瓶頸
- 遠端桌面到 SQL Server
- 開啟工作管理員(Ctrl+Shift+Esc)
- 在操作欄點擊 流程 選項卡
- 勾選 顯示所有使用者的進程
- 在操作欄點擊 中央處理器 以 CPU 使用率排序的列標題
- 確定哪些進程消耗 CPU 資源
如果非SQL Server 應用程式佔用大量 CPU,請將其從資料庫伺服器中移除。如果 sqlservr.exe 佔用 CPU 太多,請使用下列方法進行調查:
- 檢查 SQL 編譯次數/秒和 SQL 重新編譯次數/秒。如果值高於批次請求次數/秒的 10%,則表示編譯次數過多
- 查詢 sys.dm_exec_query_stats 來辨識 CPU 密集型查詢
- 審查執行計劃中是否有缺失索引或低效率操作
- 考慮添加索引以減少表格掃描
10.2 診斷記憶體問題
記憶體問題會嚴重影響 SQL Server 性能。使用以下指標診斷記憶體問題:
可用記憶體下降
如果可用兆位元組持續低於 100 MB,則作業系統面臨記憶體不足的問題tar活動。 Windows 可能會調出頁面 SQL Server 記憶體到磁碟,導致效能下降。
頁面壽命低
頁面預期壽命低於 300 秒錶示緩衝區快取週轉率較高。這意味著記憶體分配不足或查詢帶來的記憶體壓力過大。
低緩衝區快取命中率
緩衝區快取命中率低於 99% 意味著 SQL Server 頻繁地從磁碟而不是記憶體讀取資料。當緩衝池太小或 SQL Server 恢復後仍在升溫tart.
內存授予待定
如果「記憶體授予待處理」值大於 0,則表示查詢正在等待記憶體授予。這表示記憶體嚴重短缺,需要立即處理。
要解決記憶體問題:
- 配置 SQL Server 最大記憶體設置,為作業系統留出足夠的 RAM(通常為 4-8 GB,取決於伺服器大小)
- 啟用「鎖定記憶體頁面」權限 SQL Server 服務帳號
- 如果記憶體壓力持續存在,請為伺服器添加更多實體 RAM
- 識別並優化記憶體密集型查詢
10.3 解決磁碟 I/O 問題
磁碟 I/O 經常成為資料庫系統的主要效能瓶頸。請使用以下方法診斷磁碟問題:
磁碟隊列長度過長
磁碟佇列長度持續高於 2(對於 RAID,每個磁碟為 2)表示磁碟子系統無法跟上 I/O 請求。這會導致待處理操作積壓。
磁碟延遲過高
平均磁碟讀取(秒/讀取)和平均磁碟寫入(秒/寫入)值高於 10-20 毫秒錶示磁碟回應緩慢。交易日誌驅動器需要特別快的效能,理想情況下寫入時間應低於 5 毫秒。
磁碟時間百分比高
磁碟時間百分比持續高於 85% 表示磁碟飽和。磁碟花費 most 其處理 I/O 請求的時間很少,剩餘的空閒容量很少。
在解決磁碟問題之前,請先確認它們不是記憶體問題的症狀。記憶體不足 SQL Server 從磁碟讀取更多數據,人為增加磁碟指標。
要解決真正的磁碟 I/O 問題:
- 升級到更快的磁碟(SSD 而不是 HDD)
- 實施 RAID 配置以獲得更好的效能
- 將資料庫檔案、交易日誌和 tempdb 分離到不同的實體磁碟機上
- 增加更多記憶體以減少磁碟讀取
- 優化索引以減少不必要的 I/O
- 審查並優化效能不佳的查詢
10.4 解決阻塞和死鎖
當一個會話持有的鎖定阻止其他會話繼續進行時,就會發生阻塞。監控以下計數器以識別阻塞問題:
- 進程被阻止: 理想情況下應為 0
- 鎖定等待數/秒: 需要等待的鎖請求數
- 平均等待時間: 鎖等待的平均持續時間
要調查阻塞情況:
- 在 SSMS 中開啟活動監視器
- 展開 流程 部分
- 尋找非零的進程 被阻止 值
- 識別阻塞會話 ID
- 查看導致阻塞的查詢
使用 sp_WhoIsActive 進行更詳細的阻斷分析。過多的 wait_info 條目通常表示 tempdb 有爭用或阻塞問題。
為了減少阻塞:
- 最小化交易持續時間
- 使用適當的隔離級別
- 新增索引以減少鎖定持續時間
- 考慮 READ_COMMITTED_SNAPSHOT 隔離
- 審查並優化長時間運行的查詢
10.5 查詢效能問題
識別開銷昂貴的查詢對於 SQL 效能監控至關重要。請使用以下方法尋找有問題的查詢:
使用活動監視器
- 在 SSMS 中,以滑鼠右鍵按一下伺服器名稱
- 選擇 活動監視器
- 拓展 近期昂貴的查詢
- 審查具有高 CPU、持續時間或邏輯讀取的查詢
使用DMV
查詢 sys.dm_exec_query_stats 以識別資源密集型查詢:
SELECT TOP 50
total_worker_time/execution_count AS avg_cpu_time,
total_logical_reads/execution_count AS avg_logical_reads,
execution_count,
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS query_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY total_worker_time DESC
分析執行計劃
- 在 SSMS 中,開啟一個新的查詢窗口
- 點擊 顯示預計執行計劃 (Ctrl+L)或 包括實際執行計劃 (Ctrl+M)
- 執行查詢
- 檢討昂貴操作的執行計劃
- 查找表掃描、索引掃描或高 cost 操作
透過以下方式優化查詢:
- 添加適當的索引
- 重寫查詢以避免昂貴的操作
- 更新統計數據
- 使用特定的列名而不是 SELECT *
- 避免不必要的 DISTINCT 或 ORDER BY 子句
10.6 偵測並修復損壞的資料庫
資料庫損壞會導致效能下降、資料遺失和系統故障。快速檢測和修復損壞對於維護資料庫健康至關重要。
資料庫損壞指標
注意以下潛在腐敗跡象:
- 錯誤訊息 SQL Server 錯誤日誌(錯誤 823、824 或 825)
- 存取特定表時出現意外的應用程式錯誤
- 之前快速的查詢效能變慢
- SQL Server 崩潰或意外恢復tarts
- msdb.dbo.suspect_pages 表中出現的可疑頁面
使用 DBCC CHECKDB 進行檢測
DBCC 檢查數據庫 是檢測資料庫損壞的主要工具。定期運行它可及早發現問題。
監控可疑頁面
SQL Server 自動在 msdb 資料庫中記錄可疑頁面:
SELECT
database_id,
file_id,
page_id,
event_type,
error_count,
last_update_date
FROM msdb.dbo.suspect_pages
WHERE event_type IN (1,2,3)
傳回的任何行都表示存在需要立即關注的損壞問題。
預防腐敗策略
- 使用 CHECKSUM 選項啟用頁面驗證
- 維護定期資料庫備份
- 使用具有糾錯功能的可靠硬體
- 使用製造商工具監控磁碟健康狀況
- 安排定期執行 DBCC CHECKDB
- 保持 SQL Server 已更新最新補丁
恢復和修復選項
如果偵測到損壞,您可以嘗試內建工具 DBCC 檢查數據庫 修復它們。如果失敗,請使用第三方工具,例如 DataNumen SQL Recovery 可以處理嚴重的腐敗問題。
11. 先進的監控技術
11.1 查詢儲存監控
查詢存儲,於 SQL Server 2016,自動擷取查詢效能資料。它提供有關查詢行為、執行計劃和效能趨勢的寶貴見解。
啟用查詢存儲
- 在 SSMS 物件資源管理器中,以滑鼠右鍵按一下資料庫
- 選擇 產品特性
- 在操作欄點擊 查詢存儲 頁面
- In 操作模式(請求), 選擇 讀寫
- 根據需要配置其他設置
- 點擊 OK
監控查詢效能
透過物件資源管理器存取查詢儲存報表:
- 在物件資源管理器中展開資料庫
- 拓展 查詢存儲
- 從可用報告中選擇:
- 回歸查詢
- 整體資源消耗
- 資源消耗最高的查詢
- 強制計劃查詢
- 追蹤查詢
計劃回歸檢測
查詢儲存會自動偵測查詢執行計劃何時發生變化以及效能何時下降。查看「回歸查詢」報告,以確定受計劃變更影響的查詢。
強制計劃管理
當查詢儲存識別出更好的執行計劃時,強制 SQL Server 使用方法:
- 在查詢儲存中開啟查詢
- 右鍵單擊所需的計劃
- 選擇 強制計劃
這可以立即提高效能,而無需更改程式碼。
11.2 指數維護監控
索引碎片會隨著時間的推移降低查詢效能。請定期監控和維護索引,以確保最佳效能。
碎片檢查
使用此查詢檢查索引碎片:
SELECT
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
ps.avg_fragmentation_in_percent,
ps.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE ps.avg_fragmentation_in_percent > 10
AND ps.page_count > 1000
ORDER BY ps.avg_fragmentation_in_percent DESC
請在非高峰時段執行此查詢,因為它可能會佔用大量資源。
頁面密度分析
頁面密度表示索引頁的填滿程度。低密度會浪費空間並降低效能:
SELECT
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
ps.avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE ps.avg_page_space_used_in_percent < 75
重組與重建決策
根據碎片層級選擇索引維護作業:
- 碎片化 10-30%:使用 ALTER INDEX REORGANIZE
- 碎片化 > 30%:使用 ALTER INDEX REBUILD
- 碎片化率 < 10%:無須採取行動
重組操作所需的資源較少,並且可以在線運行。重建作業更為徹底,但會消耗大量資源。
11.3 資料庫統計更新
資料庫統計幫助 SQL Server的查詢最佳化器可以建立高效率的執行計劃。過時的統計資料會導致查詢效能不佳。
自動統計重建
啟用自動統計更新:
ALTER DATABASE DatabaseName SET AUTO_UPDATE_STATISTICS ON ALTER DATABASE DatabaseName SET AUTO_CREATE_STATISTICS ON
監控統計健康
檢查統計資料的最後更新時間:
SELECT
OBJECT_NAME(s.object_id) AS TableName,
s.name AS StatisticsName,
STATS_DATE(s.object_id, s.stats_id) AS LastUpdated,
sp.rows,
sp.modification_counter
FROM sys.stats s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) sp
WHERE STATS_DATE(s.object_id, s.stats_id) < DATEADD(DAY, -7, GETDATE())
ORDER BY LastUpdated
需要時手動更新統計資料:
UPDATE STATISTICS TableName WITH FULLSCAN
11.4 收集自訂效能數據
透過直接查詢 sys.dm_os_performance_counters 並將結果儲存在表中來建立自訂效能監控解決方案。
建立自訂集合腳本
建立一個預存程序來收集效能計數器資料:
CREATE PROCEDURE dbo.CollectPerformanceCounters
AS
BEGIN
INSERT INTO dbo.PerformanceHistory (
SampleTime,
CounterName,
CounterValue
)
SELECT
GETDATE(),
counter_name,
cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name IN (
'Page life expectancy',
'Batch Requests/sec',
'Buffer cache hit ratio'
)
END
使用 sys.dm_os_performance_counters
直接查詢效能計數器:
SELECT
object_name,
counter_name,
instance_name,
cntr_value,
cntr_type
FROM sys.dm_os_performance_counters
WHERE object_name LIKE '%Buffer Manager%'
ORDER BY counter_name
儲存歷史數據
建立一個表格來儲存一段時間內的效能指標:
CREATE TABLE dbo.PerformanceHistory (
ID INT IDENTITY PRIMARY KEY,
SampleTime DATETIME2 NOT NULL,
PageLifeExpectancy BIGINT,
BatchRequestsPerSec DECIMAL(18,4),
BufferCacheHitRatio DECIMAL(5,2)
)
CREATE CLUSTERED COLUMNSTORE INDEX CCI_PerformanceHistory
ON dbo.PerformanceHistory
資料透視表的儲存方法
以數據透視格式儲存數據,每個取樣時間一行,每個計數器一列。與每個計數器每個樣本儲存一行相比,這可以減少儲存空間並提高查詢效能。
11.5 多伺服器監控
對於具有多個環境 SQL Server 實例,實施集中監控。
集中監控方法
- 在單獨的伺服器上建立專用監控資料庫
- 將所有伺服器的資料收集到中央儲存庫
- 使用 SQL Server 執行收集腳本的代理作業
- 實現網路可存取的效能計數器收集
遠端伺服器監控
透過在新增計數器時指定伺服器名稱,配置效能監視器以從遠端伺服器收集資料。確保防火牆規則允許效能監視器流量。
跨伺服器報告
建立報告來比較多台伺服器的效能,以識別異常值和容量不平衡。
12。 監控 SQL Server 在雲端環境中
12.1 Azure SQL 資料庫監控
Azure SQL 資料庫提供與本機不同的內建監控功能 SQL Server.
Azure Monitor 集成
Azure Monitor 會自動從 Azure SQL 資料庫收集指標,包括:
- DTU 或 vCore 利用率
- 存儲使用率
- 連接統計
- 死鎖和超時
透過 Azure 入口網站或 Azure Monitor API 存取這些指標。
內建監控功能
Azure SQL 資料庫包括:
- 自動調整建議
- 查詢效能洞察
- 用於異常檢測的智慧洞察
- 內建警報和診斷ostICS
查詢效能洞察
此功能提供資源消耗最高的查詢、查詢持續時間分析和歷史效能趨勢的視覺化。透過 SQL 資料庫資源下的 Azure 入口網站存取它。
12.2 雲端原生監控工具
雲端平台提供其環境最佳化的本機監控解決方案:
- 適用於 Azure SQL 資料庫的 Azure Monitor 和 Application Insights
- 適用於 RDS 的 AWS CloudWatch SQL Server
- 適用於雲端的 Google Cloud 監控 SQL Server
這些工具與雲端基礎設施無縫集成,並為所有雲端資源提供統一監控。
混合式環境監控
對於跨本地端和雲端的混合部署,請使用支援兩種環境的工具,如 Redgate SQL Monitor、SolarWinds DPA 或使用集中資料收集的自訂解決方案。
12.3 雲端效能差異
雲端 SQL Server 環境具有獨特的特徵:
資源分配模型
雲端提供者使用不同的資源分配方法(DTU、vCore、無伺服器),這些方法會影響您解讀效能指標的方式。了解您的服務層級的限制和特性。
擴展考慮因素
雲端環境提供動態擴充功能。監控資源利用率,以確定何時進行擴展或縮減。許多雲端平台提供基於效能閾值的自動擴展功能。
13.自動化效能監控
13.1 SQL Server 代理職位
使用以下方式自動收集數據 SQL Server 代理作業用於持續監控,無需人工幹預。
預定的資料收集
- 在 SSMS 中,展開 SQL Server 經紀人
- 右鍵單擊 工作 並選擇 新工作
- 命名作業(例如「收集績效指標」)
- 點擊 步驟 並且新增一個新步驟
- 將類型設定為 Transact-SQL 腳本
- 輸入您的資料收集腳本
- 點擊 附表 並添加時間表
- 配置頻率(例如每 5 分鐘)
- 點擊 OK 創造就業機會
自動報告
建立產生並透過電子郵件發送績效報告的作業:
- 建立產生報表的預存程序
- 使用資料庫郵件透過電子郵件傳送報告
- 安排作業每天或每週運行
13.2 PowerShell自動化
PowerShell 提供了強大的自動化功能 SQL Server 效能監視器。
效能計數器收集腳本
$counters = @(
'\Processor(_Total)\% Processor Time',
'\Memory\Available MBytes',
'\PhysicalDisk(_Total)\Avg. Disk sec/Read'
)
$data = Get-Counter -Counter $counters -ComputerName 'SQLServer01'
$data.CounterSamples | Export-Csv 'C:\PerfLogs\counters.csv' -Append
WMI 查詢
使用 WMI 從遠端伺服器收集效能數據:
$cpu = Get-WmiObject Win32_Processor -ComputerName 'SQLServer01' $memory = Get-WmiObject Win32_OperatingSystem -ComputerName 'SQLServer01' Write-Host "CPU Usage: $($cpu.LoadPercentage)%" Write-Host "Available Memory: $([math]::Round($memory.FreePhysicalMemory/1MB,2)) GB"
自動警報
建立 PowerShell 腳本來檢查指標並在超出閾值時發送警報:
$cpuThreshold = 80
$cpu = (Get-Counter '\Processor(_Total)\% Processor Time').CounterSamples.CookedValue
if ($cpu -gt $cpuThreshold) {
Send-MailMessage -To 'dba@company.com' -Subject 'High CPU Alert' `
-Body "CPU usage is $cpu%" -SmtpServer 'smtp.company.com'
}
13.3 建立監控儀表板
使用互動式儀表板視覺化效能數據以獲得更好的洞察力。
Power BI 集成
- 將 Power BI 連接到您的效能資料表
- 為關鍵指標創建視覺化效果
- 新增時間範圍和伺服器選擇的切片器
- 將儀表板發佈到 Power BI 服務
- 配置自動刷新計劃
即時儀表板創建
使用 Grafana 等工具或自訂 Web 應用程式來建立直接查詢 DMV 和效能計數器的即時儀表板。
歷史趨勢視覺化
建立折線圖來顯示以下隨時間變化的趨勢:
- CPU利用率
- 內存使用情況
- 磁盤I / O
- 查詢效能
- 連接計數
14. 案例研究和實例
14.1 案例研究:解決記憶體壓力
症狀識別
一個製作 SQL Server 尖峰時段查詢回應緩慢。用戶抱怨應用程式超時和效能下降。
反分析
效能監視器數據顯示:
- 頁面壽命預期下降到 50 秒(正常:>300)
- 緩衝區快取命中率下降至 85%(正常:>99%)
- 記憶體授予待定值經常顯示 5-10
- 實體磁碟讀取次數/秒大幅飆升
解決步驟
- 經過 SQL Server 最大記憶體設定-發現它被設定為預設值(無限制)
- 回顧伺服器總記憶體與 Tar取得伺服器記憶體 – 顯示出明顯差距
- 配置最大伺服器內存,為作業系統保留 8 GB
- 啟用「鎖定記憶體頁面」權限 SQL Server 服務帳號
- 為伺服器添加了 32 GB 的額外 RAM
- 監控一週的效能-頁面預期壽命穩定在500秒以上
結果: 查詢回應時間提高了 60%,用戶投訴停止,應用程式效能恢復正常。
14.2 案例研究:CPU效能最佳化
症狀識別
A SQL Server 在工作時間內 CPU 使用率持續超過 90%,導致應用程式效能緩慢和使用者沮喪。
反分析
績效監測顯示:
- 處理器時間百分比平均為 92%,經常達到 100%
- 處理器佇列長度始終高於 4(伺服器有 8 個核心)
- SQL 編譯/秒是批次請求/秒的 25%(應該小於 10%)
- SQL 重新編譯/秒是批次請求/秒的 15%
解決步驟
- 使用 DMV 識別最耗 CPU 的查詢
- 分析已識別查詢的執行計劃
- 發現由於缺少索引而導致大表上的多次表掃描
- 根據執行計劃建議建立適當的索引
- 已識別導致過度編譯的動態 SQL
- 修改應用程式程式碼以使用參數化查詢
- 針對有問題的預存程序實施計畫指南
- 更新了頻繁使用的表的統計數據
結果: 工作時間內 CPU 使用率平均下降至 45%。查詢執行時間縮短了 70%。應用程式響應速度顯著提升。
14.3 案例研究:磁碟 I/O 瓶頸解決
症狀識別
用戶報告稱,在數據加載操作和晚間批處理期間,應用程式響應極其緩慢。
反分析
業績數據顯示:
- 交易日誌磁碟機上的平均磁碟秒數/寫入時間超過 45 毫秒
- 資料檔案磁碟機上的磁碟佇列長度平均為 12
- 批次作業期間磁碟時間百分比持續數小時高於 95%
- 頁面寫入/秒非常高
解決步驟
- 已驗證記憶體設定是否合適 - 未發現記憶體問題
- 分析磁碟配置-發現同一主軸組上的所有文件
- 將交易日誌分離到專用的快速 SSD 磁碟機
- 將 tempdb 移動到單獨的 SSD 驅動器
- 實作了多個 tempdb 資料檔(每個核心一個)
- 將資料檔案磁碟機升級至 RAID 10 SSD 配置
- 最佳化批次作業以使用較小的事務批次
- 新增索引以減少批次操作期間不必要的資料表掃描
結果: 平均磁碟秒/寫入時間降至 3 毫秒。磁碟佇列長度平均低於 1。批次作業完成時間縮短了 75%。
15. 未來趨勢 SQL Server 監控
15.1 人工智慧與機器學習集成
人工智慧和機器學習正在改變 SQL Server 效能監視器。
預測分析
機器學習模型根據歷史資料預測未來的資源需求。這些系統可以預測:
- 當儲存容量耗盡時
- 高峰期預計的 CPU 和記憶體需求
- 在影響用戶之前查詢效能下降
- 維護操作的最佳時間
異常檢測
人工智慧驅動的工具可以自動偵測效能指標中的異常模式。它們可以識別人類管理員可能忽略的異常,並區分正常變化和真正的問題。
自動修復
自我修復系統會在偵測到以下問題時自動解決:
- 住宅tar已停止的服務
- 在高峰負載期間重新分配資源
- 應用已知問題的修補程序
- 自動重建碎片索引
15.2 基於雲端的監控演進
雲端監控不斷發展,具有新的功能。
統一監控平台
現代平台提供單一窗口可視性:
- 本地 SQL Server 實例
- 雲-host編輯資料庫
- 混合環境
- 應用性能
- 基礎設施指標
可觀察性趨勢
從監控到可觀察性的轉變強調:
- 從輸出理解系統行為
- 關聯指標、日誌和跟踪
- 深入洞察分散式系統
- 即時問題診斷
15.3 自我修復資料庫系統
未來 SQL Server 版本將包括更多的自主能力。
自動優化
資料庫將透過以下方式不斷進行自我優化:
- 根據工作負載自動建立和刪除索引
- 調整配置設定以獲得最佳效能
- 透明地重寫低效率查詢
- 動態管理資源分配
智慧調優
先進的系統將從性能模式中學習並自動應用調整建議,從而減少對 DBA 手動幹預的需要。
16. 結論與要點
16.1 基本監測實務總結
有效 SQL Server 效能監視器需要結合工具、技術和最佳實踐的綜合方法。
關鍵反擊回顧
將監控重點放在以下重要指標:
- 記憶體:頁面預期壽命、緩衝區快取命中率、待決記憶體授予
- CPU:處理器時間百分比、處理器佇列長度
- 磁碟:平均磁碟秒/讀取與寫入、磁碟佇列長度
- SQL Server:批次請求/秒、編譯/秒、使用者連接
最佳實踐摘要
- 在正常運作期間建立基線
- 根據基線設定智慧警報閾值
- 定期檢討績效數據
- 平衡監控開銷和資料粒度
- 保留長期數據以進行趨勢分析
- 針對每個監控場景使用適當的工具
16.2 持續改進方法
SQL Server 績效監控不是一次性活動,而是一個需要不斷改進的持續過程。
定期審查週期
- 每日:檢查警報和當前表現
- 每週:回顧趨勢並發現新出現的問題
- 每月:分析長期模式和容量需求
- 每季:更新基準並審查監測有效性
掌握最新工具
保持監控工具和技術保持最新:
- 評估新的監控功能 SQL Server 更新
- 測試新興的第三方工具
- 參加培訓和會議
- 參與在 SQL Server 社區論壇
- 與團隊成員分享知識
16.3 後續步驟
實施 SQL Server 有系統地監控效能:
實施路線圖
- 第1週: 使用必要的計數器設定效能監視器
- 第2週: 建立資料收集器集以進行自動收集
- 第3週: 在正常運作期間建立基線
- 第4週: 配置關鍵閾值警報
- 月2: 實施額外的監控工具(DMV、擴充事件)
- 月3: 開發自訂儀表板和報告
- 正在進行中: 根據經驗和不斷變化的需求完善監控
更多資源
繼續學習有關 SQL Server 透過 Microsoft 文件、社群部落格和實踐操作來監控效能。嘗試不同的工具和技術,找到最適合您環境的方法。
17. 常見問題 (FAQ)
17.1 什麼是 most 重要 SQL Server 要監控的效能計數器?
併購ost 批評 SQL Server 性能計數器包括:
- 記憶體:頁面預期壽命(應> 300 秒)和緩衝區快取命中率(應> 99%)
- CPU:處理器時間百分比(持續值 <75%)和處理器佇列長度(每個核心應 <2)
- 磁碟:平均磁碟秒/讀取和寫入(應<10-20ms)和磁碟佇列長度(每個磁碟應<2)
- SQL Server:批次請求/秒、SQL 編譯/秒和待處理的記憶體授予(應為 0)
這些計數器提供對系統健康狀況的全面洞察並幫助快速識別瓶頸。
17.2 我應該多久收集一次性能數據?
收集頻率取決於您的監控目標:
- 基線監測:每1分鐘(60秒)一次
- 主動故障排除:每 15-30 秒短時間
- 長期趨勢:每 5 分鐘
避免連續運行高頻收集,因為這會影響效能並產生過多數據。常規監控應使用較長的間隔,僅在調查特定問題時使用較短的間隔。
17.3 性能監視器和 SQL Server 分析器?
效能監視器和 SQL Server 分析器有不同的用途:
性能監視器:
- 監控系統和 SQL Server 性能計數器
- 追蹤資源利用率(CPU、記憶體、磁碟)
- 低開銷,適合持續監控
- 提供隨時間變化的聚合指標
SQL Server 分析器:
- 追蹤個人 SQL Server 事件和查詢
- 捕獲詳細的查詢執行信息
- 開銷較大,不建議持續使用
- 最適合解決特定查詢問題
- 已棄用,改用擴充事件
使用效能監視器進行整體系統監視,使用擴充事件(而非分析器)進行詳細的查詢層級分析。
17.4 效能監視器是否會影響 SQL Server 性能?
如果配置正確,效能監視器對 SQL Server 性能,通常開銷不到 2%。然而,過度監控可能會導致以下問題:
- 計數器過多會增加開銷
- 採樣間隔非常短(少於 15 秒)會對資源造成壓力
- 持續高頻採集產生較大的日誌文件
為了盡量減少影響:
- 僅監控必要的計數器
- 使用適當的採樣間隔(常規監測為 60 秒)
- 將日誌儲存在與資料庫檔案分開的磁碟機上
- 在非尖峰時段安排資源密集型監控
17.5 我應該保留效能監控資料多久?
保留取決於您的分析需求和儲存容量:
- 最低配置: 3 個月用於解決近期問題
- 推薦: 1-2 年的產能規劃與趨勢分析
- 最佳的: 如果儲存允許,可以無限期保存,因為歷史資料會隨著時間的推移而變得更有價值
效能計數器資料壓縮效果良好,佔用空間相對較少。考慮將舊資料歸檔到單獨的儲存空間,而不是刪除。許多組織發現,多年的歷史數據對於容量規劃和識別長期趨勢非常有價值。
17.6 關鍵性能計數器的良好閾值是多少?
建議的警報閾值:
- 內存授予待定:當 > 0 時發出警報
- 頁面壽命預期:< 300 秒時發出警報
- % 處理器時間:當處理器時間超過 80% 並持續 5 分鐘時發出警報
- 處理器佇列長度:當每個核心 > 2 時發出警報
- 平均磁碟秒/讀取或寫入:> 20ms 時發出警報
- 磁碟佇列長度:當每個磁碟 > 2 時發出警報
- 阻塞進程:當 > 5 時發出警報
根據您的基準資料和特定工作負載特徵調整這些閾值。在一個環境中正常的值在另一個環境中可能表示有問題。
17.7 如何監控 SQL Server 遠端執行?
監控遠端 SQL Server 使用這些方法的實例:
- 性能監視器: 新增計數器時指定遠端電腦名稱
- 電源外殼: 將 -ComputerName 參數與 Get-Counter 結合使用
- 車輛管理局 (DMV): 透過SSMS連接遠端伺服器並查詢DMV
- 第三方工具: Most 監控工具支援遠端伺服器監控
確保防火牆規則允許效能監視器流量,並且您在遠端伺服器上擁有適當的權限。對於多台伺服器,請考慮使用專用監控伺服器和資料庫實施集中監控。
17.8 最好的免費工具是什麼 SQL Server 效能監視器?
有幾種優秀的免費工具可用於監控 SQL Server 性能:
- Windows 效能監視器: 內建、全面、可靠
- SSMS 活動監視器: 即時監控,無需額外安裝
- 擴展事件: 內建輕量級事件監控 SQL Server
- sp_WhoIsActive: 用於詳細活動監控的熱門免費儲存過程
- DBA Dash: 功能全面的開源監控工具
- SQL監視: 開源且具有近乎即時的監控功能
對於米ost 組織,效能監視器與 SSMS 工具和 sp_WhoIsActive 相結合,無需額外費用即可提供出色的監控功能ost.
17.9 如何導出 PerfMon 資料進行分析?
使用以下方法匯出效能監視器資料:
匯出為 CSV:
- 打開效能監視器並載入日誌文件
- 右鍵單擊圖形並選擇 數據另存為
- 選擇 文字檔案(逗號分隔)(.csv)
- 選擇位置並儲存
- 在 Excel 中開啟進行分析
使用重新登入命令:
relog input.blg -f csv -o output.csv
此命令列公用程式將二進位日誌檔案 (.blg) 轉換為 CSV 格式,以便在電子表格應用程式中更輕鬆地進行分析。
17.10 什麼時候應該使用第三方監控工具而不是內建選項?
在以下情況下考慮使用第三方工具:
- 管理大量 SQL Server 實例(10+)
- 需要跨多個資料中心進行集中監控
- 需要預測分析或異常檢測等高階功能
- 希望將警報與事件管理系統集成
- 要求合規報告和歷史分析
- 缺乏 DBA 資源來建立和維護客製化解決方案
- 監控異質資料庫環境(SQL Server, Oracle、MySQL 等)
內建工具非常適合小型環境,或者您擁有經驗豐富的 DBA 來開發自訂監控解決方案。第三方工具則透過節省時間、提供高級功能和專業支援來提供價值。
18.其他資源
18.1 官方文檔
Microsoft 提供了大量文檔 SQL Server 效能監視器:
- SQL Server 效能監視器文件: https://learn.microsoft.com/en-us/sql/relational-databases/performance-monitor/
- 動態管理視圖: https://learn.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/
- 擴展事件: https://learn.microsoft.com/en-us/sql/relational-databases/extended-events/
- 查詢儲存: https://learn.microsoft.com/en-us/sql/relational-databases/performance/monitoring-performance-by-using-the-query-store
- 效能調整與監控: https://learn.microsoft.com/en-us/sql/relational-databases/performance/
18.2 推薦的工具和下載
必備工具 SQL Server 效能監視器:
- PAL 工具: https://github.com/clinthuffman/PAL
- sp_WhoIsActive: http://whoisactive.com/
- DBA Dash: https://dbadash.com/
- SQL監視: https://github.com/marcingminski/sqlwatch
- 急救包(Brent Ozar): https://www.brentozar.com/first-aid/
- SQL Server 管理工作室: https://learn.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
18.3 社區資源
學習 SQL Server 社區:
- SQL Server 中央: https://www.sqlservercentral.com/
- 布倫特·奧扎爾博客: https://www.brentozar.com/blog/
- SQL小屋: https://www.sqlshack.com/
- MSSQL提示: https://www.mssqltips.com/
- Reddit r/SQLServer: https://www.reddit.com/r/SQLServer/
- 堆棧溢出 SQL Server 標籤: https://stackoverflow.com/questions/tagged/sql-server
這些資源提供了經驗豐富的教程、故障排除建議和最佳實踐 SQL Server 專業人士。參與社群論壇可以幫助您學習他人的經驗並分享自己的知識。
關於作者
元盛 是一位資深資料庫管理員 (DBA),擁有超過 10 年的 SQL Server 環境和企業資料庫管理。他成功解決了金融服務、醫療保健和製造業等行業的數百個資料庫恢復場景。
袁專長於 SQL Server 資料庫復原 高可用性解決方案以及性能優化。他擁有豐富的實務經驗,包括管理數TB資料庫、實施等。 始終在線可用性組並為關鍵業務系統開發自動化備份和復原策略。
透過他的技術專長和實踐方法,袁致力於創建全面的指南,幫助資料庫管理員和 IT 專業人員解決複雜的 SQL Server 高效應對挑戰。他始終掌握最新 SQL Server 版本和微軟不斷發展的資料庫技術,定期測試恢復場景以確保他的建議反映現實世界的最佳實踐。
有關於的問題 SQL Server 恢復或需要額外的資料庫故障排除指導?袁歡迎 回饋和建議 用於改進這些技術資源。