Bài viết sau đây giải thích sự khác biệt chính giữa bảng Heap và bảng Clustered.
Khi làm việc với các bảng trong SQL Server, người dùng thường phải đối mặt với tình thế tiến thoái lưỡng nan khi sử dụng bảng nhóm hoặc bảng đống. Các bảng không có chỉ mục nhóm được gọi là Bảng Heap và những bảng có chỉ mục nhóm được gọi là Bảng nhóm. Chỉ mục được nhóm về cơ bản sắp xếp lại cách thức mà các bản ghi được lưu trữ vật lý trong một bảng. Các trang dữ liệu được chứa trong các nút lá của một chỉ mục được nhóm.
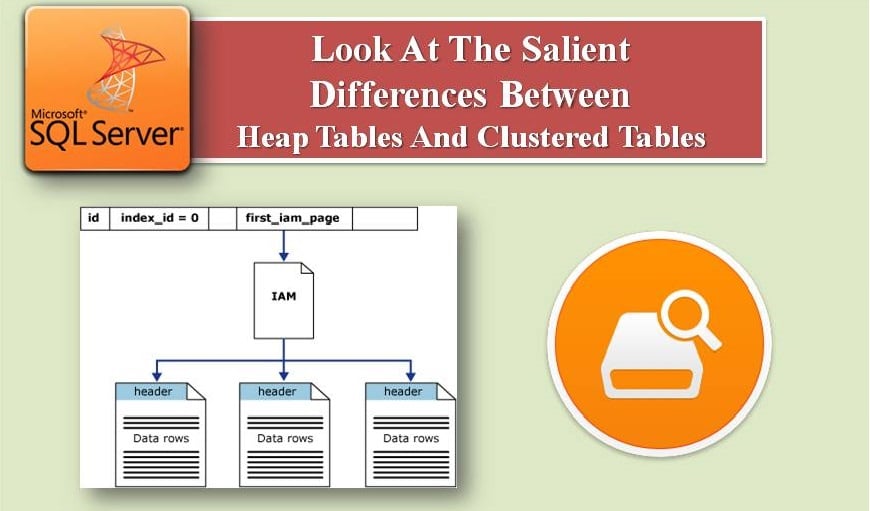
Bài viết thảo luận về hai loại bảng này một cách chi tiết hơn.
Bảng nhóm và bảng đống
Các bảng nhóm cung cấp cho người dùng nhiều lợi ích hơn bảng heap vì chúng giúp người dùng sử dụng chỉ mục để tìm hàng nhanh hơn bảng heap và lưu trữ vật lý dữ liệu/bản ghi bằng cách xây dựng lại chỉ mục nhóm.
Dữ liệu vật lý của bạn có thể bị phân mảnh nếu có nhiều hoạt động CHÈN, XÓA và CẬP NHẬT đối với các bảng trong dữ liệu của bạn. Được biết, dữ liệu bị phân mảnh có thể làm tăng thêm không gian bị lãng phí và không mong muốn vì nếu bạn chạy một truy vấn thì nó phải đọc thêm một số trang vì hiện có nhiều trang đầy một phần. Hãy tìm cách giải quyết vấn đề phân mảnh dữ liệu.
Sự khác biệt giữa Heap và Clustered Table
Vấn đề phân mảnh có thể được khắc phục bằng cách xác định nhu cầu có chỉ mục nhóm trong/các bảng của bạn hay không. Rốt cuộc, đó là chỉ mục nhóm hoặc heap điều chỉnh bộ nhớ vật lý của bảng của bạn. Bất kỳ bảng nào trong cơ sở dữ liệu của bạn chỉ có thể có một loại chỉ mục. Để đưa ra lựa chọn, chúng ta phải hiểu sự khác biệt cơ bản giữa hai điều này như sau.
- Trong heap, không có thứ tự lưu trữ dữ liệu nhưng trong Clustered, việc lưu trữ dữ liệu có thứ tự tùy thuộc vào khóa chỉ mục của cụm.
- Các trang dữ liệu không được liên kết trong Heap trong khi trong bảng Clustered, chúng được liên kết và có quyền truy cập tuần tự nhanh hơn.
- Heap có 0 giá trị index_id và Clustered có 1 giá trị index_id cho chế độ xem danh mục sys.indexes
- Clustered Index lấy dữ liệu nhanh hơn heap table vì có Clustered Index key
Phân mảnh
Dựa trên sự khác biệt giữa Clustered và Heap Table, người ta có thể giải quyết vấn đề phân mảnh. Sự phân mảnh xảy ra do sử dụng các hoạt động INSERT, DELETE và UPDATE. Tuy nhiên, nếu bạn có Bảng Heap và chỉ có hoạt động INSERT thì sự phân mảnh sẽ không xảy ra. Nếu bạn đang sử dụng khóa chỉ mục tuần tự (Giá trị nhận dạng) và chỉ có INSERTS, thì chỉ mục nhóm của bạn sẽ không bị phân mảnh. Nhưng nếu bạn sử dụng nhiều INSERTS hoặc DELETES thì các bảng sẽ bị phân mảnh.
Vì vậy, nên sử dụng Chỉ mục cụm vì nó phụ thuộc vào khóa Chỉ mục và tiêu tốn ít dung lượng hơn. Các bản ghi mới có thể được ghi vào các trang hiện có trong không gian trống có sẵn.
Để xác định việc sử dụng bảng heap hoặc bảng nhóm, bạn cũng có thể thử chạy DBCC SHOWCONTIG hoặc new DMV vì cả hai lệnh này có thể cung cấp cho bạn thông tin chi tiết về các vấn đề phân mảnh trong bảng của bạn. Trong bảng nhóm, sự phân mảnh có thể được giải quyết bằng cách tổ chức lại hoặc xây dựng lại chỉ mục nhóm của bạn.
Đầu tư vào một SQL Server sửa công cụ là phải cho các công ty sử dụng MS SQL Server cơ sở dữ liệu trên các máy chủ sản xuất của họ. Trên thực tế, nó có thể chứng minh là cứu cánh trong trường hợp cơ sở dữ liệu gặp sự cố.
Giới thiệu tác giả:
Victor Simon là một chuyên gia phục hồi dữ liệu trong DataNumen, Inc., công ty hàng đầu thế giới về công nghệ khôi phục dữ liệu, bao gồm sửa chữa mdb và các sản phẩm phần mềm phục hồi sql. Để biết thêm thông tin, hãy truy cập https://www.datanumen.com/