Seuraava artikkeli selittää tärkeimmät erot Heap-taulukoiden ja klusteroitujen taulukoiden välillä.
Kun työskentelet taulukoiden kanssa SQL Server, käyttäjät kohtaavat usein ongelman käyttää klusteroituja pöytiä tai kasapöytiä. Taulukoita, joissa ei ole klustereita, kutsutaan kasan taulukoiksi ja ryhmiteltyjä hakemistoja ryhmiteltyiksi. Klusteroitu hakemisto järjestää periaatteessa tavan, jolla tietueet tallennetaan fyysisesti taulukkoon. Tietosivut sisältyvät klusteroidun hakemiston lehtisolmuihin.
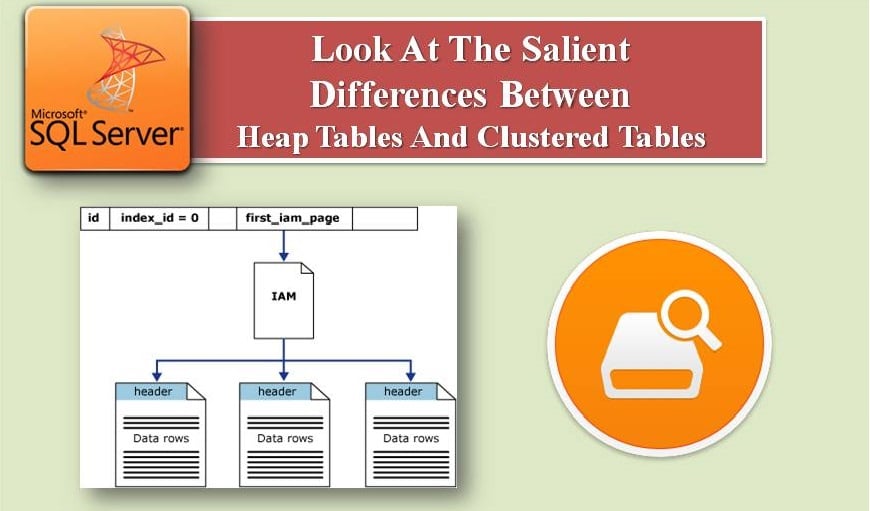
Artikkelissa käsitellään näitä kahta taulukotyyppiä yksityiskohtaisemmin.
Ryhmitetyt ja kasapöydät
Klusteroidut taulukot tarjoavat käyttäjille enemmän etuja kuin kasan taulukot, koska ne auttavat käyttäjiä hakemistoissa etsimään rivejä nopeammin kuin kasan taulukot ja tallentamaan tiedot / tietueet fyysisesti rakentamalla klusteroidun indeksin.
Fyysiset tietosi voivat pirstoutua, jos tietojesi taulukoita vastaan on enemmän INSERT-, DELETE- ja UPDATE-toimintoja. Tiedetään, että pirstoutunut data voi lisätä hukkaan ja ei-toivottuun tilaan, koska jos suoritat kyselyn, sen on luettava useita sivuja, koska osittain kokonaisia sivuja on nyt. Selvitetään tapoja ratkaista tietojen pirstoutuminen.
Ero kasan ja klusteroidun pöydän välillä
Sirpaloitumisongelma voidaan ratkaista määrittämällä tarve pitää ryhmittynyt indeksi taulukoissasi. Loppujen lopuksi se on klusteroitu tai kasaindeksi, joka säätelee pöydän fyysistä tallennustilaa. Kaikilla tietokannan taulukoilla voi olla vain yksi hakemistotyyppi. Valinnan tekemiseksi meidän on ymmärrettävä näiden kahden peruserot, jotka ovat seuraavat.
- Kasaan ei ole järjestystä tietojen tallentamisessa, mutta klusteroidussa tietojen tallennuksessa on järjestys klusteroidun hakemiston avaimen mukaan.
- Tietosivuja ei ole linkitetty Heapiin, kun taas Clustered-taulukossa ne on linkitetty ja peräkkäinen käyttö on nopeampaa.
- Koneella on 0 index_id-arvo ja Clusterilla on 1 index_id-arvo sys.indexes-luettelonäkymässä
- Klusteroitu hakemisto hakee tietoja nopeammin kuin kasan taulukko, koska siellä on Clustered Index -avain
Hajanaisuus
Klustereiden ja kasan taulukoiden välisten erojen perusteella voidaan ratkaista sirpaloitumisen ongelma. Sirpaloituminen tapahtuu INSERT-, DELETE- ja UPDATE-toimintojen käytön vuoksi. Jos sinulla on kuitenkin Heap Table ja siellä on vain INSERT-toimintaa, pirstoutumista ei tapahdu. Jos käytät peräkkäistä hakemistoavainta (Identity Value) ja sinulla on vain INSERTS, klusteroitu hakemisto ei pirstoutu. Mutta jos käytät paljon INSERTS tai DELETES, taulukot pirstaloituvat.
Joten on suositeltavaa käyttää klusteroitua hakemistoa, koska se riippuu indeksiavaimesta ja vie vähemmän tilaa. Uudet tietueet voidaan kirjoittaa jo olemassa oleville sivuille käytettävissä olevaan vapaaseen tilaan.
Voit määrittää joko kasan tai klusteroidun taulukon käytön kokeilemalla myös DBCC SHOWCONTIG: n tai uuden DMV: n käyttöä, koska molemmat komennot voivat antaa sinulle tietoa taulukoiden pirstoutumisongelmista. Ryhmätaulukossa pirstoutuminen voidaan ratkaista järjestelemällä tai rakentamalla uudelleen klusteroitu hakemisto.
Sijoittaminen a SQL Server korjaus työkalu on pakollinen yrityksille, jotka käyttävät jäsenvaltiota SQL Server tuotantopalvelimillaan. Itse asiassa se voi osoittautua hengenpelastajaksi tietokannan kaatumisen yhteydessä.
Tekijän esittely:
Victor Simon on tietojen palauttamisen asiantuntija DataNumen, Inc., joka on maailman johtava tietojen palautustekniikoissa, mukaan lukien korjaus mdb ja sql-palautusohjelmistotuotteet. Lisätietoja osoitteessa https://www.datanumen.com/