Sljedeći članak objašnjava ključne razlike između tablica hrpe i klasteriranih tablica.
Dok radite sa stolovima u SQL Server, korisnici se često suočavaju s dilemom da koriste grupisane tabele ili heap tabele. Tabele koje nemaju grupisane indekse zovu se tabele hrpe, a one koje imaju grupisane indekse nazivaju se klasterizovane tabele. Grupirani indeks u osnovi mijenja način na koji se zapisi fizički pohranjuju u tablicu. Stranice podataka sadržane su u listovima čvorova grupiranog indeksa.
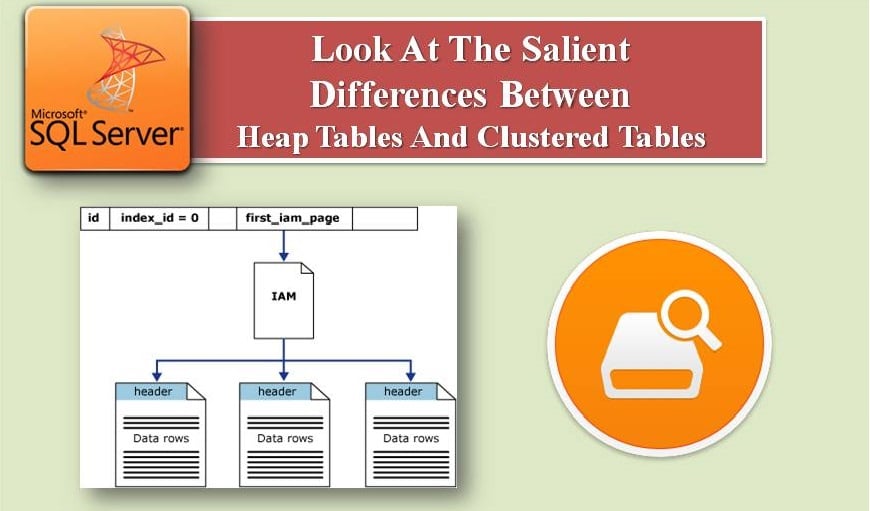
U članku se detaljnije razmatraju ove dvije vrste tablica.
Grupirane i skupne tabele
Grupirane tablice pružaju korisnicima više prednosti od hrpa tablica jer pomažu korisnicima da koriste indekse da brže pronađu redove od tablica hrpe i fizički pohranjuju podatke/zapise ponovnom izgradnjom klasteriziranog indeksa.
Vaši fizički podaci mogu postati fragmentirani ako postoji više aktivnosti INSERT, DELETE i UPDATE prema tabelama u vašim podacima. Poznato je da fragmentirani podaci mogu dodati izgubljeni i nepoželjni prostor jer ako pokrenete upit on mora pročitati još nekoliko stranica jer sada ima više djelomično punih stranica. Hajde da pronađemo načine da rešimo problem fragmentacije podataka.
Razlika između hrpe i grupisane tablice
Problem fragmentacije se može riješiti utvrđivanjem potrebe za klasteriziranim indeksom u vašoj tablici ili ne. Na kraju krajeva, klasterizovani ili heap indeks reguliše fizičku pohranu vaše tabele. Svaka tabela u vašoj bazi podataka može imati samo jedan tip indeksa. Da bismo napravili izbor, moramo razumjeti osnovne razlike između ova dva, a to su sljedeće.
- U hrpi, nema redoslijeda u pohranjivanju podataka, ali u klasteriranom, pohranjivanje podataka ima redoslijed ovisno o klasteriziranom indeksnom ključu.
- Stranice sa podacima nisu povezane u hrpi, dok su u grupisanoj tabeli povezane i postoji brži sekvencijalni pristup.
- Hrpa ima 0 vrijednosti index_id, a grupirani imaju 1 vrijednost index_id za prikaz kataloga sys.indexes
- Grupirani indeks dohvaća podatke brže od hrpe tablice jer postoji ključ klasteriziranog indeksa
Fragmentacija
Na osnovu razlika između Clustered i Heap Tables može se riješiti problem fragmentacije. Fragmentacija se javlja zbog upotrebe aktivnosti INSERT, DELETE i UPDATE. Međutim, ako imate Heap Table i postoji samo INSERT aktivnost, tada neće doći do fragmentacije. Ako koristite sekvencijalni indeksni ključ (vrijednost identiteta) i imate samo INSERTS, onda se vaš klasterirani indeks neće fragmentirati. Ali ako koristite puno INSERTS ili DELETES onda će tabele postati fragmentirane.
Stoga se savjetuje da koristite Clustered Index jer ovisi o ključu indeksa i troši manje prostora. Novi zapisi se mogu upisivati na već postojeće stranice u slobodnom prostoru.
Da biste odredili upotrebu gomile ili grupisane tablice, također možete pokušati pokrenuti DBCC SHOWCONTIG ili novi DMV jer vam obje ove naredbe mogu dati uvid u probleme fragmentacije u vašim tablicama. U grupisanoj tablici, fragmentacija se može riješiti reorganizacijom ili ponovnom izgradnjom vašeg klasteriziranog indeksa.
Ulaganje u a SQL Server Popravak alat je obavezan za kompanije koje koriste MS SQL Server baze podataka na njihovim proizvodnim serverima. U stvari, može se pokazati kao spas u slučaju pada baze podataka.
Uvod za autora:
Victor Simon je stručnjak za oporavak podataka DataNumen, Inc., koji je svjetski lider u tehnologijama za oporavak podataka, uključujući popraviti mdb i sql softverski proizvodi za oporavak. Za više informacija posjetite https://www.datanumen.com/