Следващата статия обяснява ключовите разлики между купчините таблици и клъстерираните таблици.
Докато работите с таблици в SQL Server, потребителите често се сблъскват с дилемата да използват клъстерирани таблици или таблици от купчини. Таблици, които нямат клъстерирани индекси, се наричат купчини, а тези с клъстерирани индекси се наричат клъстерирани таблици. Клъстерираният индекс основно подрежда начина, по който записите се съхраняват физически в таблица. Страниците с данни се съдържат в листовите възли на клъстериран индекс.
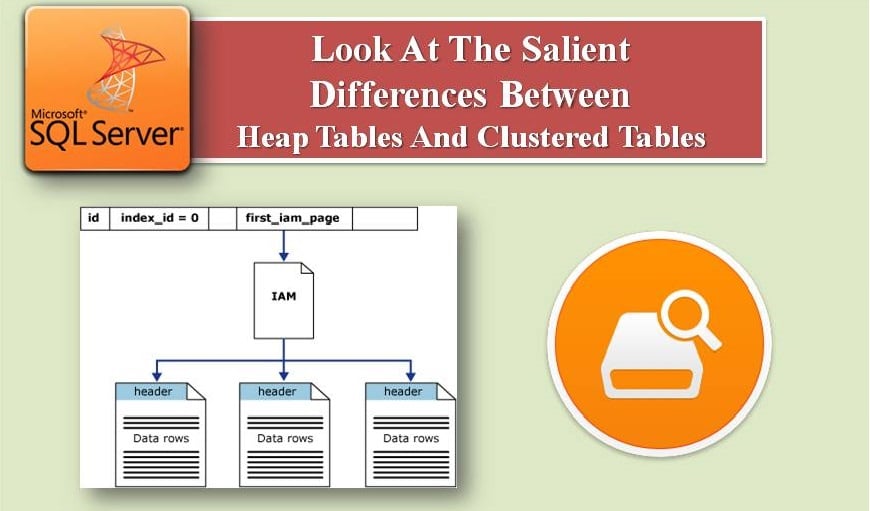
Статията разглежда тези два типа таблици по-подробно.
Клъстерни и купчини
Клъстерираните таблици осигуряват на потребителите повече предимства от таблиците на купчини, тъй като помагат на потребителите при използване на индекси да намират редове по-бързо от таблиците на купчини и физически да съхраняват данните / записите чрез възстановяване на клъстерирания индекс.
Вашите физически данни могат да станат фрагментирани, ако има повече дейности INSERT, DELETE и UPDATE спрямо таблиците във вашите данни. Известно е, че фрагментираните данни могат да добавят към загубено и нежелано пространство, защото ако изпълните заявка, тя трябва да прочете още няколко страници, тъй като сега има по-частично пълни страници. Нека да разберем начини за решаване на проблема с фрагментацията на данните.
Разлика между купчина и клъстерирана таблица
Проблемът с фрагментацията може да бъде решен, като се определи необходимостта да имате клъстериран индекс във вашата таблица / и или не. В края на краищата, индексът на клъстерите или купчината регулира физическото съхранение на вашата маса. Всяка таблица във вашата база данни може да има само един тип индекс. За да направим избор, трябва да разберем основните разлики между тези две, които са както следва.
- В купчина няма ред за съхраняване на данни, но в Clustered съхранението на данни има ред в зависимост от клъстерирания индексен ключ.
- Страниците с данни не са свързани в купчина, докато в клъстеризираната таблица те са свързани и има по-бърз последователен достъп.
- Купчината има 0 index_id стойност, а Clustered има 1 index_id стойност за изглед на каталог sys.indexes
- Клъстерираният индекс извлича данни по-бързо от таблицата на купчината, тъй като има клавишен клавиш за индекс
Раздробяване
Въз основа на разликите между клъстерираните и купчините таблици може да се реши проблемът с фрагментацията. Фрагментацията възниква поради използването на дейности INSERT, DELETE и UPDATE. Ако обаче имате Heap Table и има само INSERT активност, тогава фрагментация няма да възникне. Ако използвате последователен ключ на индекса (Identity Value) и имате само INSERTS, тогава вашият клъстерен индекс няма да бъде фрагментиран. Но ако използвате много INSERTS или DELETES, тогава таблиците ще станат фрагментирани.
Затова се препоръчва да се използва клъстериран индекс, тъй като зависи от клавиша Index и консумира по-малко място. Нови записи могат да бъдат записани на вече съществуващи страници в наличното свободно пространство.
За да определите използването на купчина или клъстеризирана таблица, можете също да опитате да стартирате DBCC SHOWCONTIG или нов DMV, тъй като и двете команди могат да ви дадат представа относно проблемите с фрагментацията във вашите таблици. В клъстеризираната таблица фрагментацията може да бъде разрешена чрез реорганизация или възстановяване на вашия клъстериран индекс.
Инвестиране в a SQL Server ремонт инструментът е задължителен за компаниите, които използват ДЧ SQL Server база данни на техните производствени сървъри. Всъщност може да се окаже спасител в случай на срив на базата данни.
Въведение на автора:
Виктор Саймън е експерт по възстановяване на данни в DataNumen, Inc., която е световен лидер в технологиите за възстановяване на данни, включително ремонт mdb и sql софтуерни продукти за възстановяване. За повече информация посетете https://www.datanumen.com/